
画像生成AI『Stable Diffusion』に挑戦!
画像生成AI『Stable Diffusion』に挑戦!
導入手順とPCスペックについて解説
この記事ではStable Diffusionをローカル環境で利用する方法と、利用する上でおすすめのPCについて解説します。
Stable Diffusionをローカル環境で実行するうえでの推奨PCスペックから、基本的な導入までを実機を用いて解説しますので、これからStable Diffusionを利用したい方は最後までご覧になってください。
※ FRONTIERでは、Stable Diffusionの導入や操作、それに伴う不具合等に関するサポートは提供しておりません。ご不明点については、製品の公式サイトをご参照ください。
introduction
画像生成AIとは?

近年様々な業界で話題となっているAI技術。現在多くの人間が行っている作業や仕事を、AIが取って代わるのではないかとも言われています。例えば『ChatGPT』はユーザーのコメントに対して、文章を出力してくれるAIです。それに対して画像生成AIの場合はユーザーのコメントに対して、文章ではなく画像を出力してくれると言う物になります。
日本国内でも『Stable Diffusion(ステーブル・ディフュージョン)』や『Midjourney(ミッドジャーニー)』が多用されるようになり、デザインやクリエイティブ分野での影響や活用法などが注目されています。以前まではWeb上で多用されるアイコンやイメージ画像にしても、自力で制作できない場合は有料の画像素材サイトを利用する、あるいは写真家やイラストレーターに個別で依頼するということが一般的でした。現在では画像生成AIが登場し、これを活用することで、自力で画像を作成できなかったユーザーの助けになるのです。
日本国内でも『Stable Diffusion(ステーブル・ディフュージョン)』や『Midjourney(ミッドジャーニー)』が多用されるようになり、デザインやクリエイティブ分野での影響や活用法などが注目されています。以前まではWeb上で多用されるアイコンやイメージ画像にしても、自力で制作できない場合は有料の画像素材サイトを利用する、あるいは写真家やイラストレーターに個別で依頼するということが一般的でした。現在では画像生成AIが登場し、これを活用することで、自力で画像を作成できなかったユーザーの助けになるのです。
生成された画像の著作権
および商用利用について
および商用利用について
一方で画像生成AIの登場によって危機感を持っているのは、それまで画像素材を制作し提供していた写真家やイラストレーターなどのクリエイターであり、既に著作権をめぐってトラブルとなっています。基本的に著作権は制作者=クリエイターに帰属している物であり、許可なく複製したり模造したりすることは権利侵害となります。いわゆる二次創作なども、厳密に言えば著作権侵害となりえるのですが、多くの場合は権利者が申し立てする事なく黙認しています。ただ人間による複製や模倣と違い、AIは人間では不可能なスピードで描画が可能で、学習することで真贋の判別がつかないほど同じ画風の画像を出力します。言い換えれば画像生成AIは、贋作を大量に生み出されるツールとなり得るものであり、クリエイターの社会的な価値や信用を失う可能性が大いにあります。
以上の事から、「著作権があって商用利用が認められていない画像を、学習元として利用した生成画像を一般公開や販売をすると、著作権侵害や利益侵害になりえる」といえます。今回紹介する「Stable Diffusion」はテキスト入力で画像を生成し、個人利用の範疇である限りは、他者の著作権を侵害しないとされています。ただし追加学習などを利用する際には注意が必要です。
以上の事から、「著作権があって商用利用が認められていない画像を、学習元として利用した生成画像を一般公開や販売をすると、著作権侵害や利益侵害になりえる」といえます。今回紹介する「Stable Diffusion」はテキスト入力で画像を生成し、個人利用の範疇である限りは、他者の著作権を侵害しないとされています。ただし追加学習などを利用する際には注意が必要です。
『Stable Diffusion』とは?
「Stable Diffusion」は訓練済みのAIモデルを利用した画像生成AIの一種です。画像の生成には画像を連想させる英単語テキストを入力することが必要で、様々な画像を制作できます。生成の際に入力する英単語テキストを「プロンプト(prompt)」と言い、英文に理解力のあるユーザーであれば、より自身が思い描くイメージに近い画像を生成しやすくなります。一応日本語入力でも生成は可能ですが、精度は低くなる傾向にあります。
生成される画像の特徴
Stable Diffusionで生成される画像は、入力された文章や単語の数に依存しています。例えば「犬」と入力した場合、もちろん犬の画像が生成されるわけですが、そこには犬種、背景、画風などの指定が無いため、画像生成AIは様々な犬の画像をランダムで生成してしまいます。これではユーザーのイメージに近い画像を入手する確率は低くなります。そこで「犬、ポメラニアン、白毛、草原、実写…」という感じで、より具体的な条件などを付けくわえることで絞り込みをしていくのです。

「犬」と入力した場合

「犬、ポメラニアン、白毛、草原、実写…」と入力した場合
利用方法はWebアプリケーションと
ローカルの2種類
ローカルの2種類
Stable Diffusion自体はオープンソースAIであり、誰でも利用することが可能となっています。しかしStable Diffusionを動作させるには高い処理能力が必要となり、全ての人がそこまで高い処理能力を持った端末を持っていません。
そこで実際にStable Diffusionを利用する場合『ブラウザのWebアプリケーション環境』と、『使用端末内で完結させるローカル環境』の2種類の方法が考えられます。
Webアプリケーション環境というのは、「Hugging Face」「Dream Studio」「Mage」などのWeb上のサービスを利用するもので、これはStable Diffusionを動作させるための処理能力を外部から借りている状態です。クラウド環境とも呼ばれます。それに対してローカル環境は、実際に所有しているパソコンにStable Diffusionを導入し、全ての処理を自力で行うものです。
そこで実際にStable Diffusionを利用する場合『ブラウザのWebアプリケーション環境』と、『使用端末内で完結させるローカル環境』の2種類の方法が考えられます。
Webアプリケーション環境というのは、「Hugging Face」「Dream Studio」「Mage」などのWeb上のサービスを利用するもので、これはStable Diffusionを動作させるための処理能力を外部から借りている状態です。クラウド環境とも呼ばれます。それに対してローカル環境は、実際に所有しているパソコンにStable Diffusionを導入し、全ての処理を自力で行うものです。
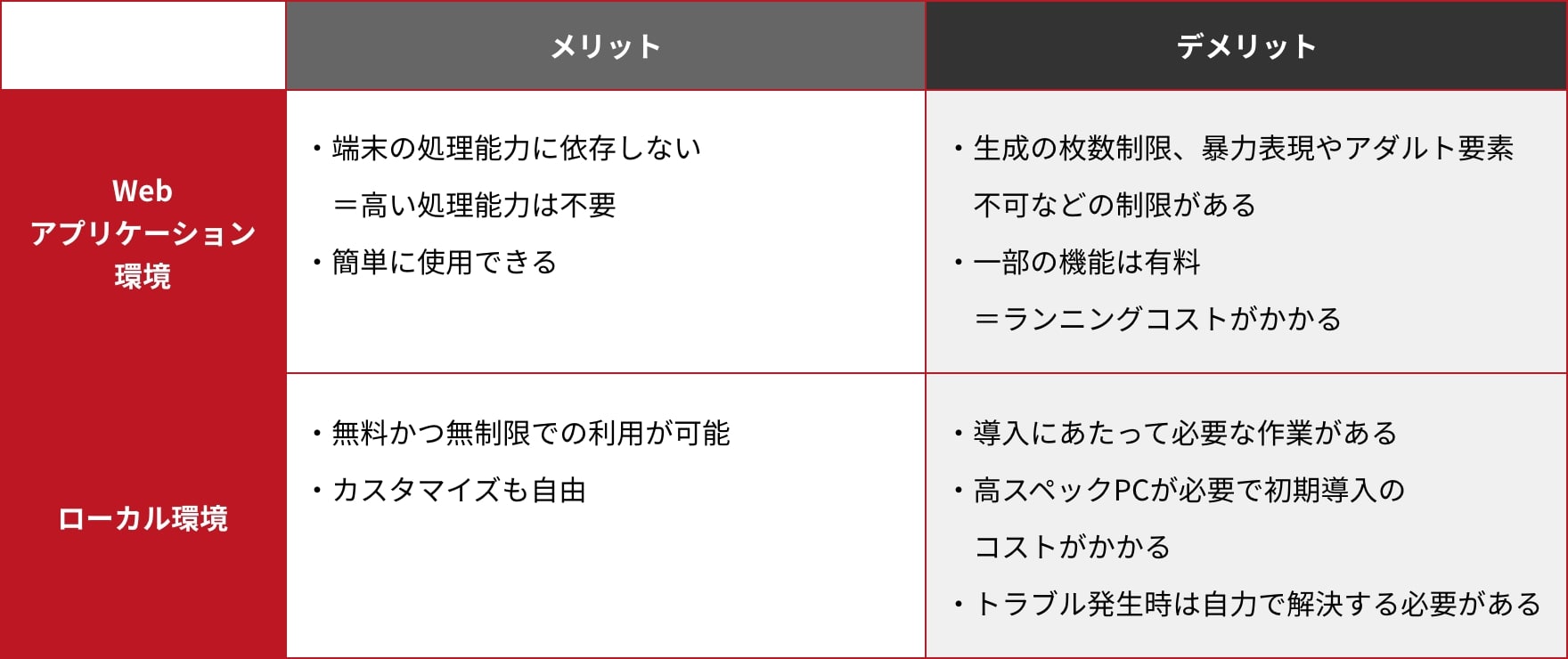
またそれぞれの環境については、双方にメリットとデメリットがあります。
Webアプリケーション環境は手軽さが魅力な反面、機能面での制約があるため自由度では劣ります。
ローカル環境は自由度が高い一方で、導入初期に必要な作業があり、必要な処理能力を満たすパソコンを用意するには知識と費用が必要となります。
Webアプリケーション環境は手軽さが魅力な反面、機能面での制約があるため自由度では劣ります。
ローカル環境は自由度が高い一方で、導入初期に必要な作業があり、必要な処理能力を満たすパソコンを用意するには知識と費用が必要となります。
Stable Diffusion の
ローカル環境への導入
ローカル環境への導入
Stable Diffusionを利用するにあたって、自由度とカスタマイズ性の高さに魅力を感じるのであれば、ローカル環境への導入がおすすめです。ただStable Diffusionを快適に動作させるためには、必要な条件が存在します。この条件を間違えてしまうと画像生成に時間がかかったり、エラーによって出力されないなどのトラブルの原因に繋がります。
高性能なGPUを持つデスクトップPC推奨
Stable Diffusionの処理をローカル環境で行うには、以下の様な条件があります。
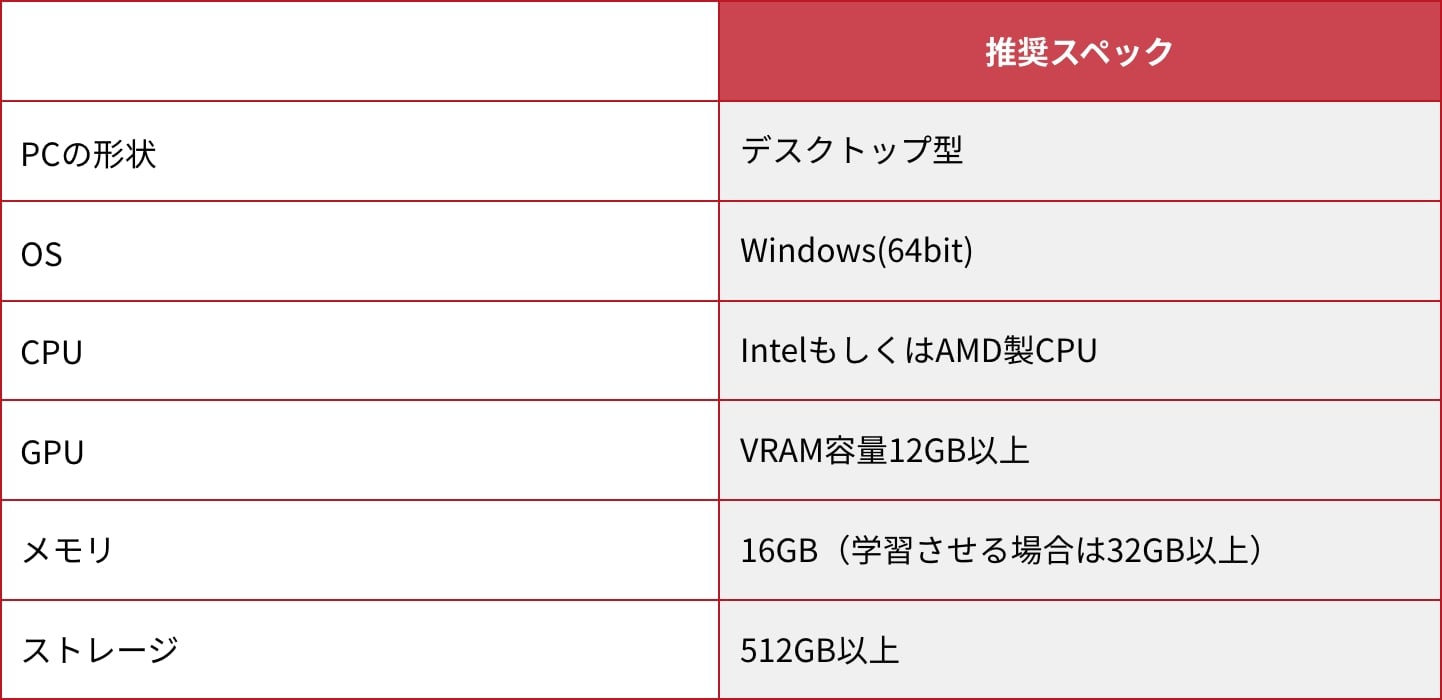
デスクトップPCが推奨される理由としては、大型で高性能なGPUを搭載するためです。理論上はGPUさえあればノートPCでも良いのですが、画像生成中は非常に高い負荷がかかり発熱するので、大きな冷却ファンが搭載できるデスクトップPCが有利です。OSに関してはmac OSでも動作はするのですが、M1/M2チップ搭載macではGPU性能が不足するため、画像生成に時間がかかります。CPUに関して必要な性能についての指定はありませんが、後述するGPUの性能から考えれば、「Intel Core i5~i7」もしくは「AMD Ryzen 5~7」辺りを採用するとバランスが良いでしょう。メモリやストレージに関しては、大きなデータを扱うために大きな容量が必要です。後から増設する事も可能なパーツですが、増設する作業の容易さでもデスクトップPCが有利となります。
使用するGPUは「VRAM容量 12GB以上の NVIDIA製GPU」
Stable DiffusionではGPUを主に使用しますので、GPU性能が高いほど快適に動作します。ただGPUを選ぶ上で気を付けておきたいのは、VRAM容量とGPUメーカーです。VRAMとはGPUに搭載されている専用ビデオメモリの事で、GPUの処理能力と同様にVRAM容量の大きさによっても生成速度や動作安定性に影響がでます。またStable Diffusionは、NVIDIA製GPUに搭載されているCUDAコアへの依存度が高いです。そのためCUDAコアを持たないAMD製GPUでは生成速度が遅く、VRAM容量不足エラーになりやすいという問題があり、2024年1月時点でも最適化不足が目立ちます。
以上のことを踏まえると、「VRAM容量12GB以上のNVIDIA製GPUを搭載した、Windows OSのデスクトップPC」が、Stable Diffusionを動作させるのに適したパソコンということになります。
以上のことを踏まえると、「VRAM容量12GB以上のNVIDIA製GPUを搭載した、Windows OSのデスクトップPC」が、Stable Diffusionを動作させるのに適したパソコンということになります。
使用するPC
『FRGAG-B760/CG1』について
『FRGAG-B760/CG1』について



今回Stable Diffusionの導入・検証に使用するPCは「FRGAG-B760/CG1」となります。
基本的な外観や構成としては、フロンティアにおけるゲーミングPC「GAシリーズ」と共通しているところも多いです。ただFRGAG-B760/CG1はクリエイターPCという位置付けであり、それに伴ってメモリ周りが強化されています。Stable DiffusionではGPUに搭載されているVRAM容量が、生成速度や動作安定性に影響を与えるのは先述の通り。そのため搭載されているGPUはフルHDゲーミング対応のGeForce RTX4060 Tiで間違いないのですが、搭載されているVRAM容量に関しては通常の2倍の16GB版となっています。また一般的なフルHD対応ゲーミングPCと比べ、メインメモリも32GBとこちらも通常の2倍の容量を持っており、Stable Diffusionでの追加学習にも対応しています。
基本的な外観や構成としては、フロンティアにおけるゲーミングPC「GAシリーズ」と共通しているところも多いです。ただFRGAG-B760/CG1はクリエイターPCという位置付けであり、それに伴ってメモリ周りが強化されています。Stable DiffusionではGPUに搭載されているVRAM容量が、生成速度や動作安定性に影響を与えるのは先述の通り。そのため搭載されているGPUはフルHDゲーミング対応のGeForce RTX4060 Tiで間違いないのですが、搭載されているVRAM容量に関しては通常の2倍の16GB版となっています。また一般的なフルHD対応ゲーミングPCと比べ、メインメモリも32GBとこちらも通常の2倍の容量を持っており、Stable Diffusionでの追加学習にも対応しています。
PCの電力設定
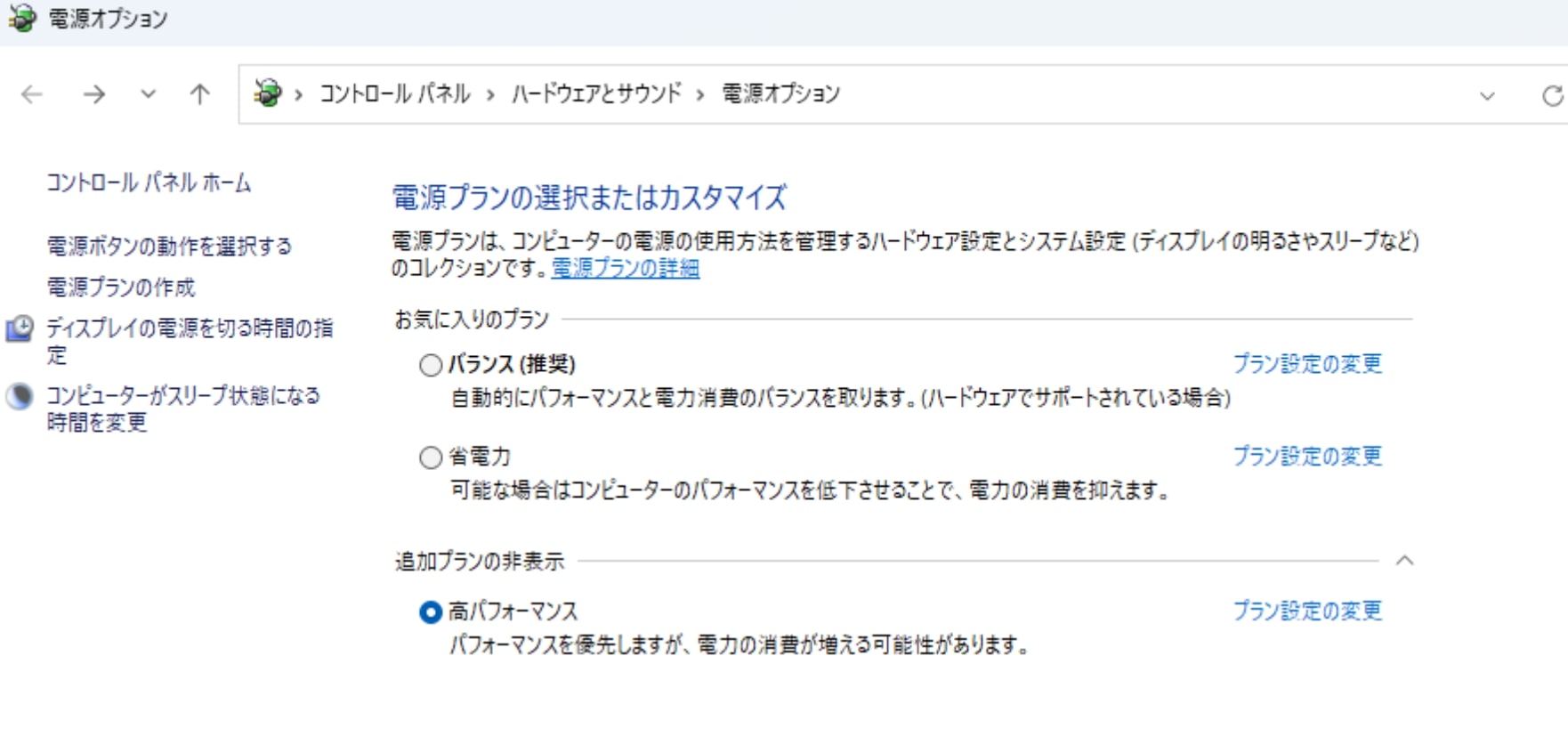
画像生成時にはGPUに大きな負荷がかかり、必要とされる電力も大きくなります。そのためGPUへの供給電力を最大化し、性能を引き出すための電力設定を行います。まずWindowsの設定からコントロールパネルを経由して電力オプションを開き、「高パフォーマンス」を選択します。稀に非表示になっていることもありますが、追加プランの部分に隠れていることが多いです。
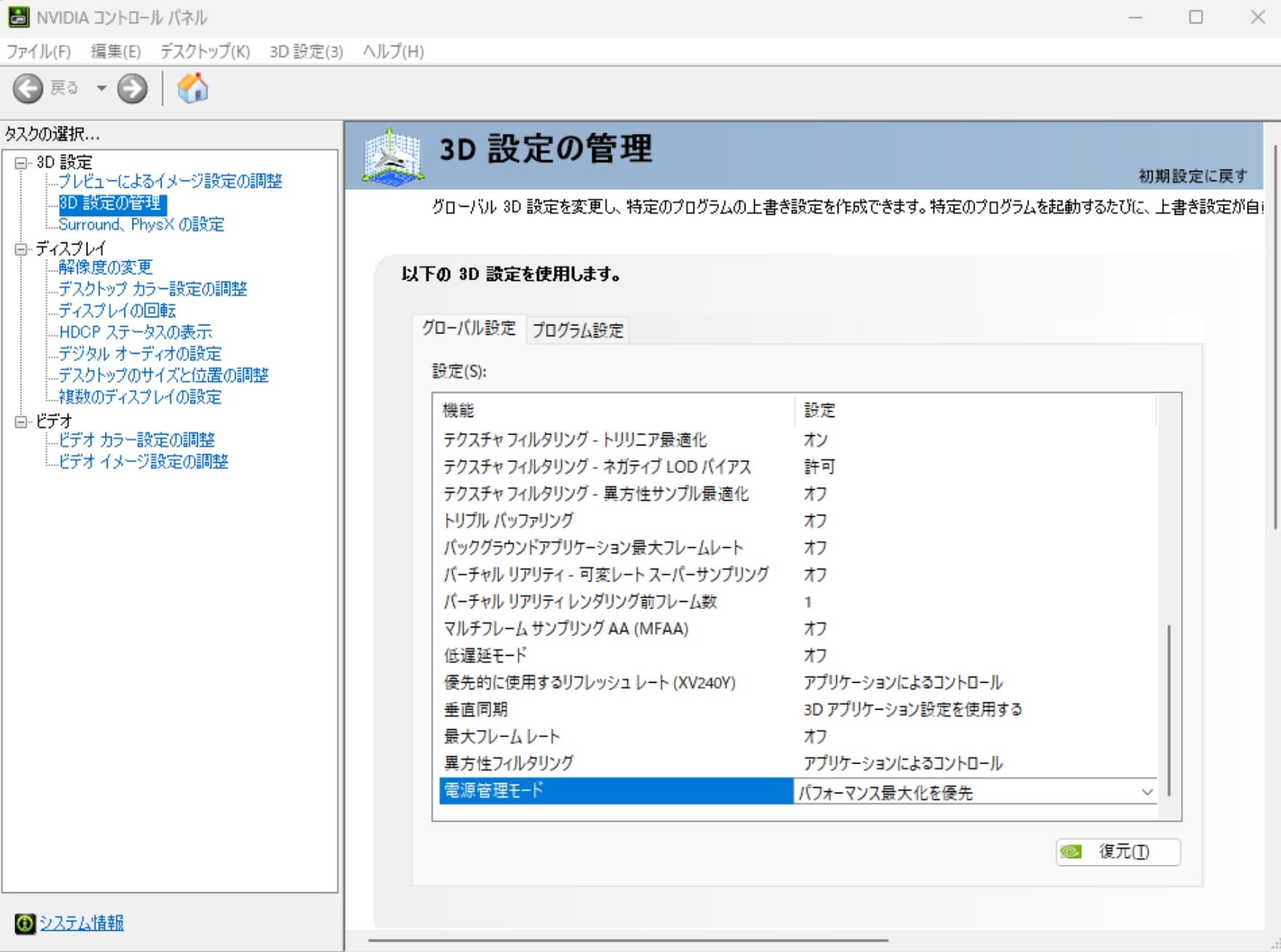
次にホーム画面で右クリック→NVIDIAコントロールパネルを開き、3D設定の管理のグローバル設定から電力管理モードを「パフォーマンス最大化を優先」を選択します。
ローカル環境PCへの
Stable Diffusion 導入手順
Stable Diffusion 導入手順
次にローカル環境へのStable Diffusionの導入手順について紹介します。今回はStable DiffusionをWeb UIで表示する「AUTOMATIC 1111」を利用します。
以下の3つをインストールしていきます。
Python(3.10.6)
Git
Stable Diffusion
Python(3.10.6)のインストール
-
Pythonの公式サイトにアクセスし、下にスクロールしていくと「Python3.10.6」の欄がでてきます。
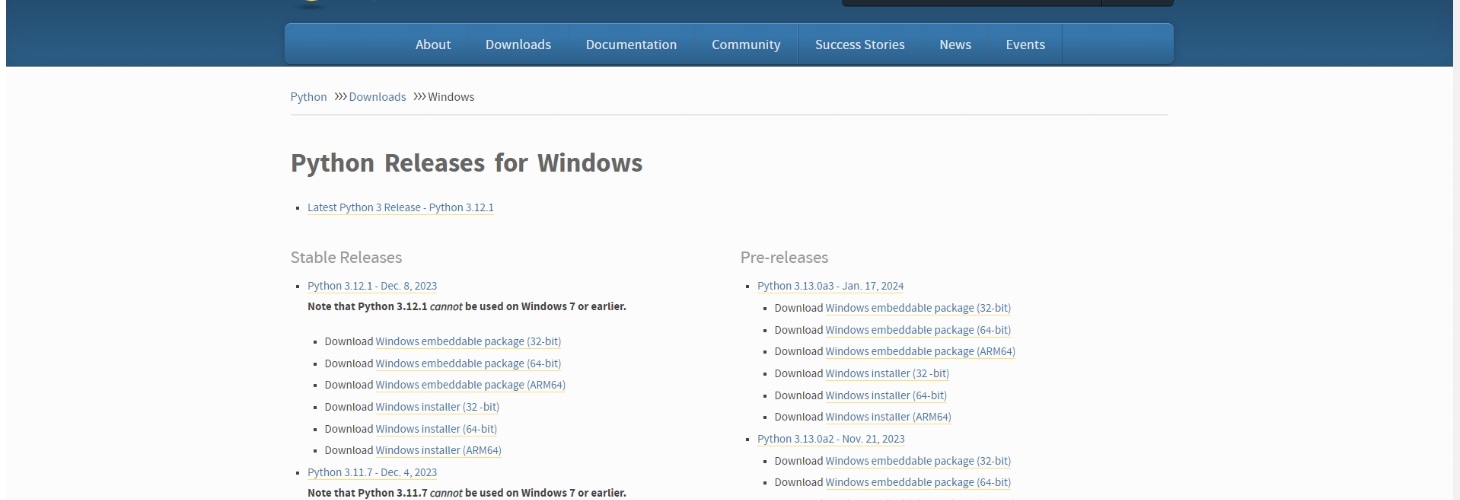
-
この中の「Download Windows installer (64-bit)」をクリックしてインストールを開始しますします。
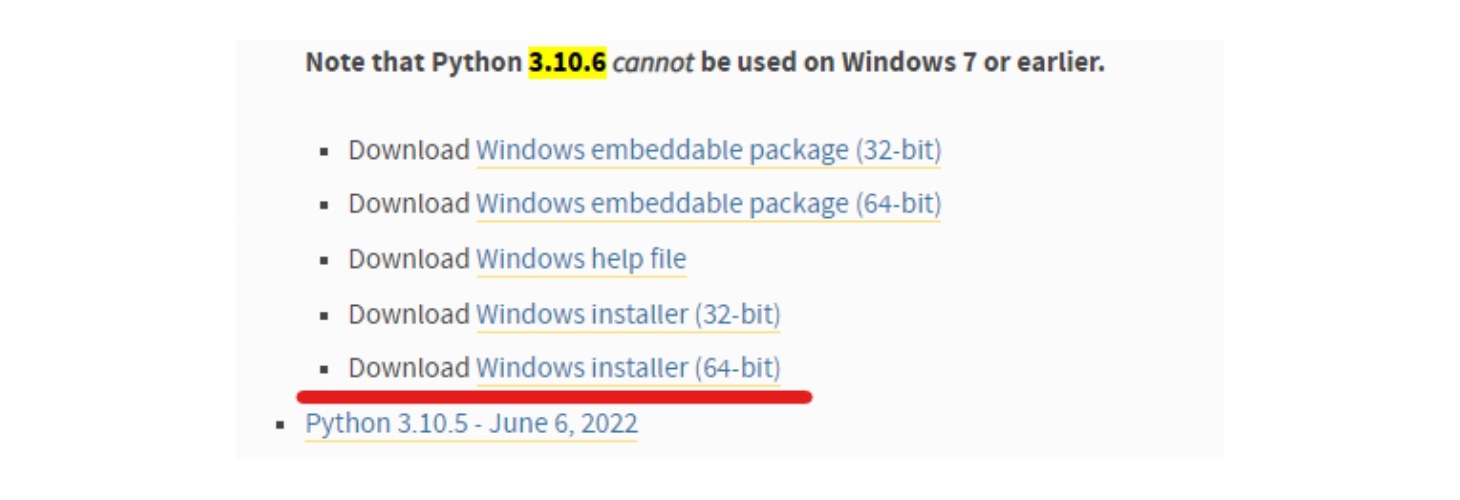
-
インストーラーが起動したら、「Add Python 3.10 to PATH」にチェックを入れてから、「Install Now」をクリックしてインストールを開始します。
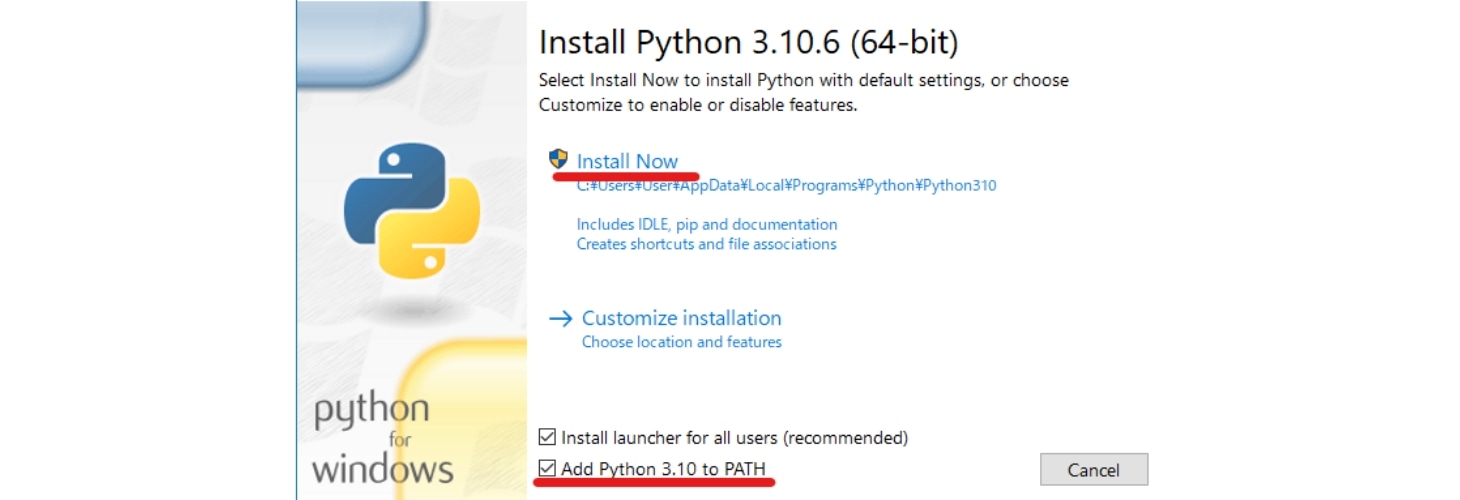
-
インストールが完了すると、上のような画面が表示されるので「Close」で閉じます。
-
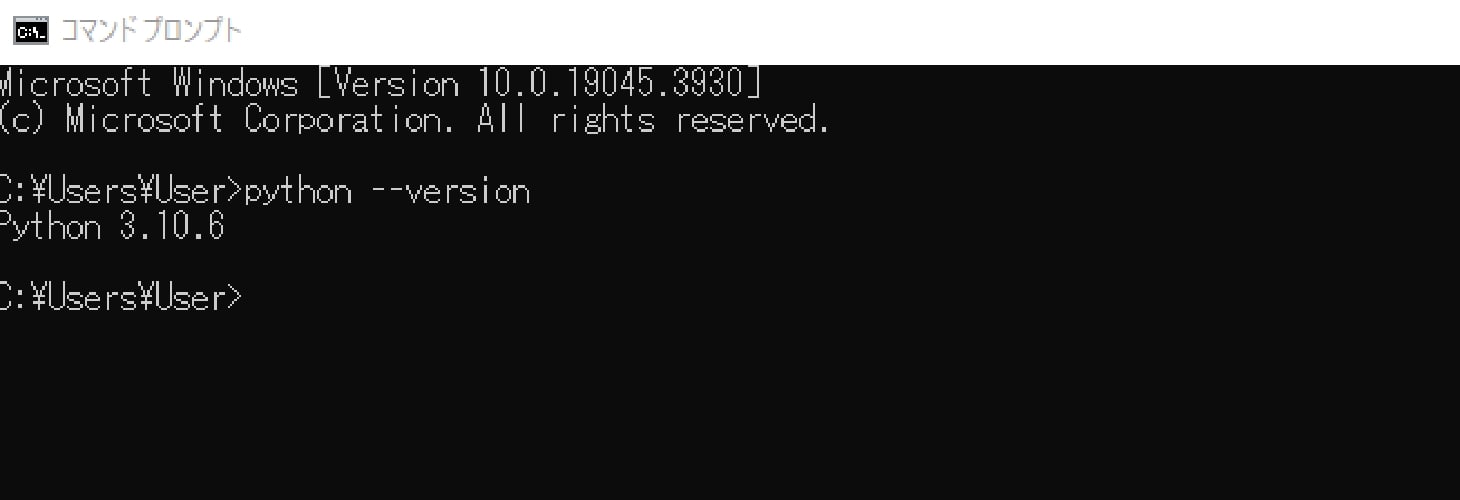
確認としてコマンドプロンプトを実行し、「python -version」と入力することで、pythonのバージョンを確認することができます。 この時にpythonのバージョンが違っていたり、あるいはバージョンが表示されない時はアンインストールしてやり直ししてください。
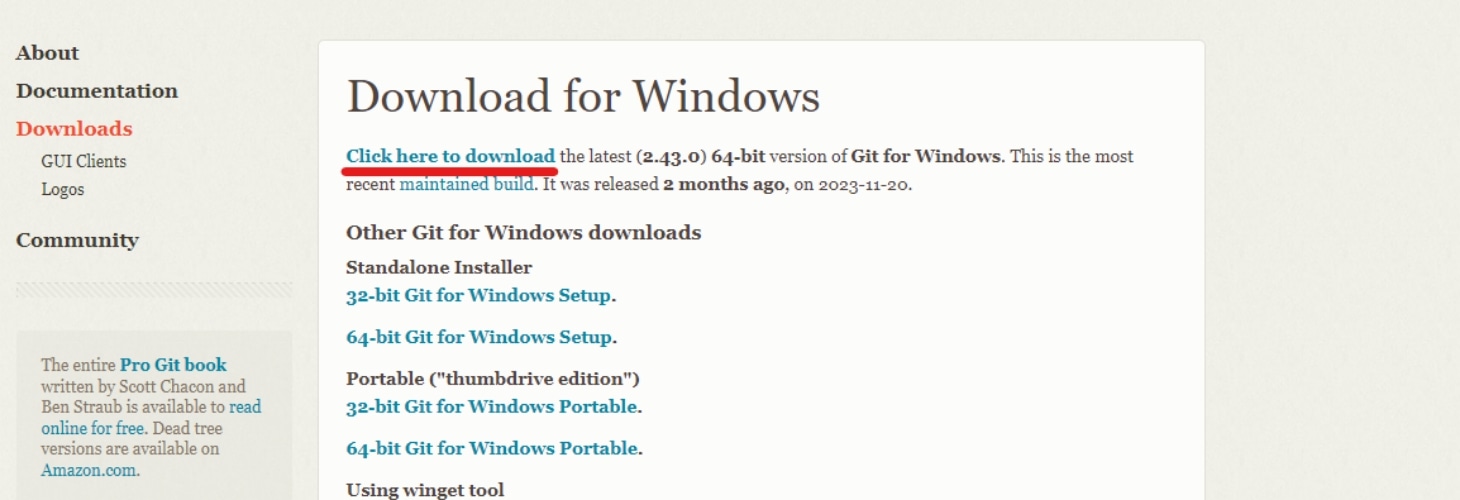
GitのインストールGitはプログラムのファイル管理をするためのシステムとなります。
-
公式サイトの「Click here to download」をクリックします。
-
セットアップのためのインストーラーが起動しますので、この後いくつかの画面が出るのでNextもしくはinstallを押していきます。
-
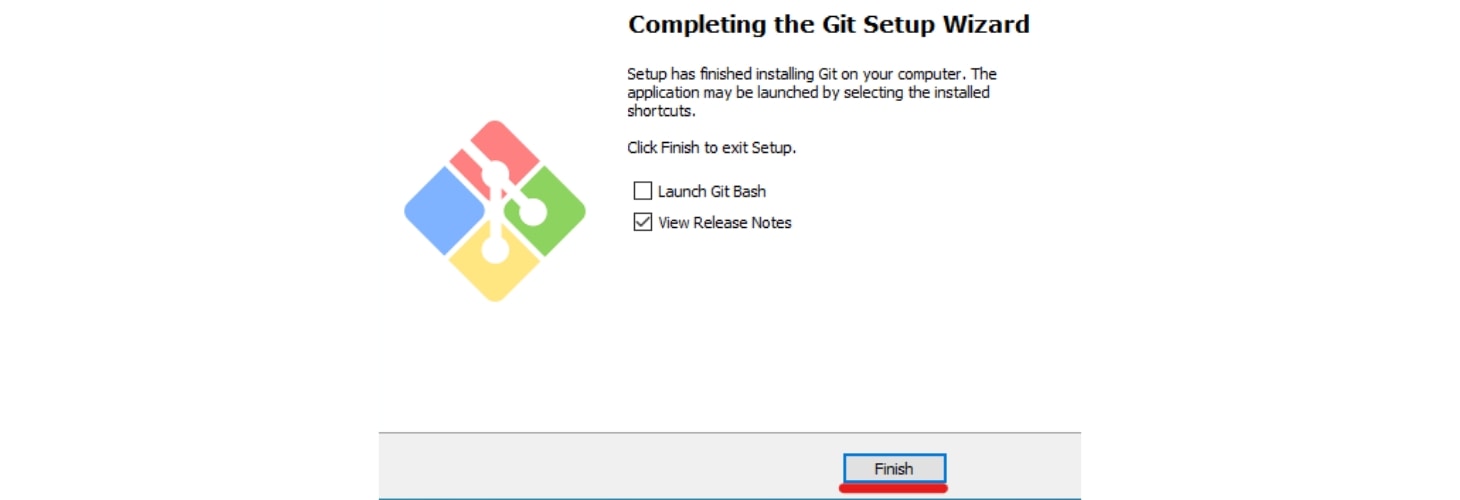
インストールが完了したらこのような画面に変わるので、「Finish」をクリックして画面を閉じます。どのアプリケーションで開くかという画面が出ましたら、普段使っているWebブラウザを指定してください。
-
するとブラウザ上にパッチノートに関するサイトが開きますが、閉じてしまって大丈夫です。
Stable Diffusionのインストール
-
大きな空き容量のあるストレージを用意し、インストールするフォルダを作成。作成したフォルダ上で右クリック→「Open Git Bash here」をクリックします。Open Git Bash hereが見えない場合は、「その他のオプション」をクリックすると表示されます。
後述するモデルなどの導入も考慮すると、ストレージ容量は大きい方が良いです。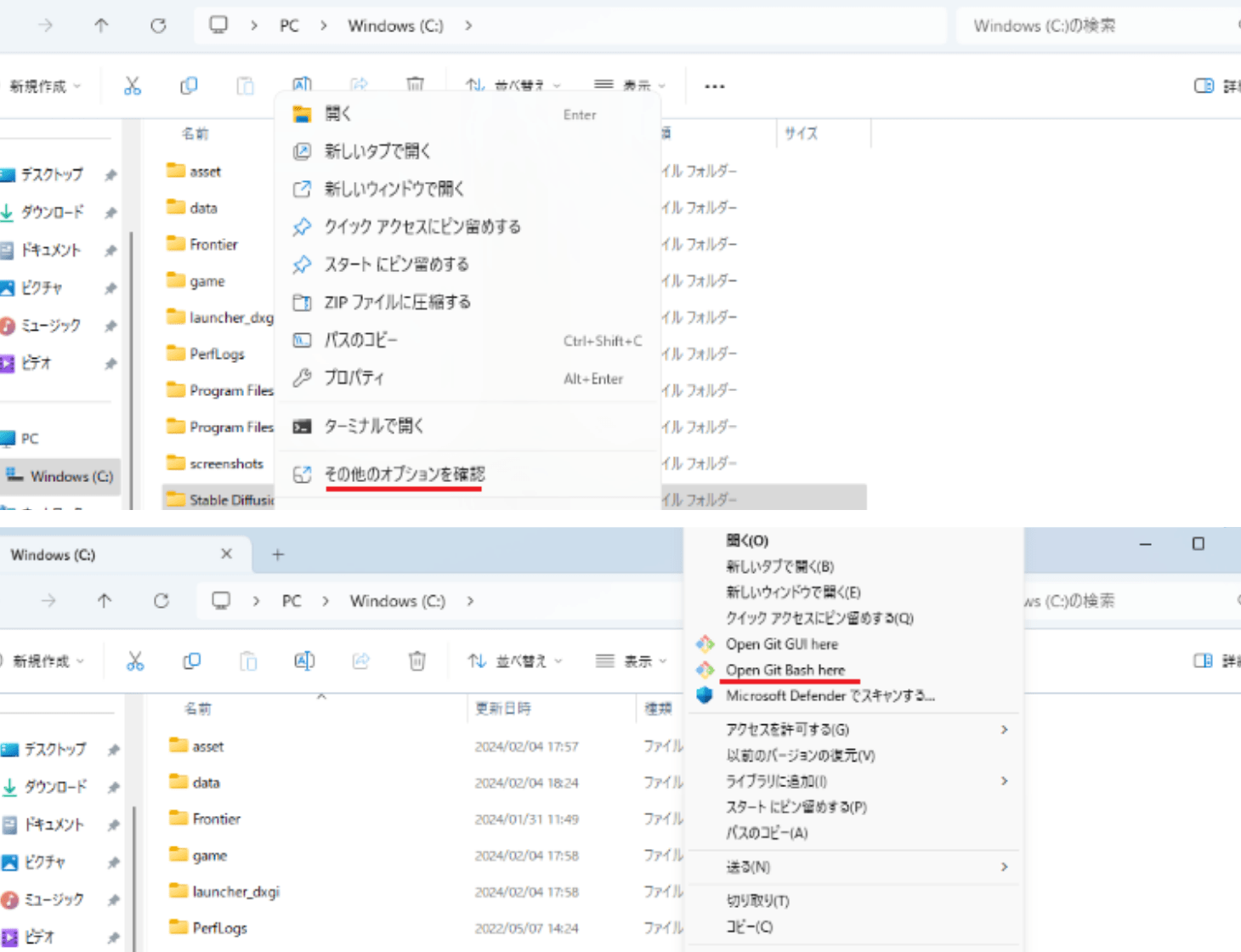
-
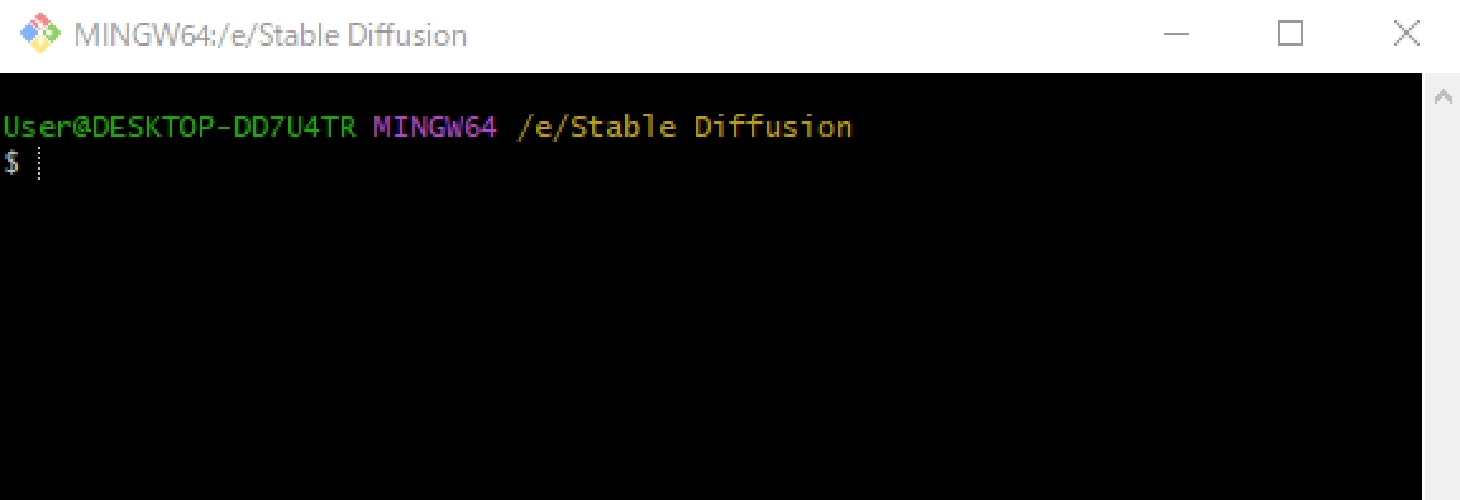
コマンドプロンプトが開くので、以下のコマンドを実行します。 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 右クリック→「paste」で貼り付けが可能です。コマンドが止まったらインストール完了です。
-
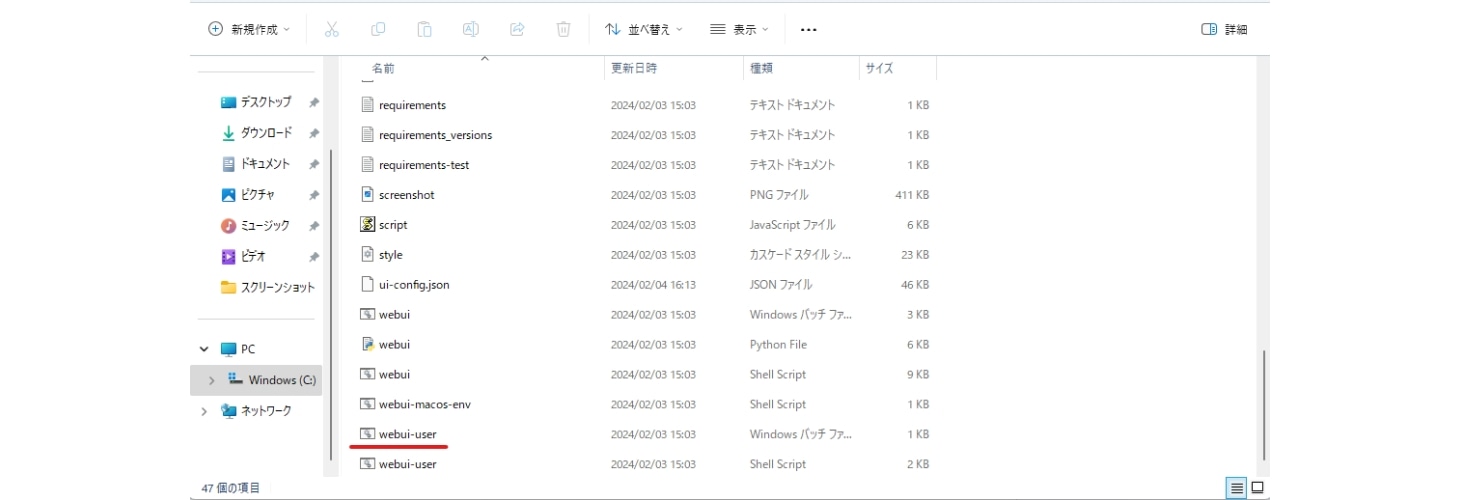
Stable Diffusionを利用する際は、作成したフォルダ→「stable-diffusion-webui」→下から2番目の「webui-user(batファイル)」をクリックしてコマンドを実行させます。
-
初回はコマンドが完了するまで10分以上時間がかかりますが、完了するとブラウザでStable Diffusionが自動で起動します。 自動で起動しない場合は「http://127.0.0.1:7860/」のURLから開くことも可能です。
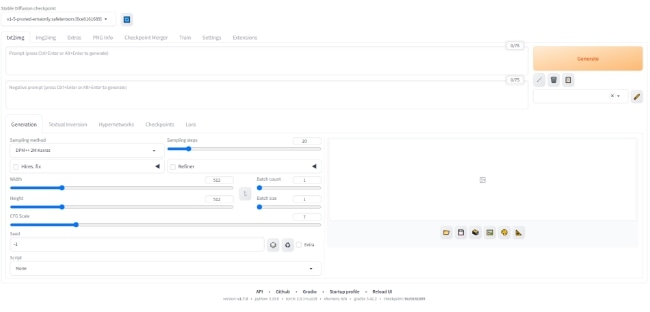

以上が「AUTOMATIC 1111」を利用したStable Diffusion導入手順です。
ちなみにコマンドウィンドウは閉じてしまうと機能が停止してしまうので、起動後は最小化しておくのがおすすめです。
またStable Diffusionを取り巻く環境は、日々アップデートが行われています。新しいバージョンを導入することで利便性が高まりますが、逆に互換性が失われることで利用できなくなる要素が出ることもあるので注意が必要です。
ちなみにコマンドウィンドウは閉じてしまうと機能が停止してしまうので、起動後は最小化しておくのがおすすめです。
またStable Diffusionを取り巻く環境は、日々アップデートが行われています。新しいバージョンを導入することで利便性が高まりますが、逆に互換性が失われることで利用できなくなる要素が出ることもあるので注意が必要です。
Stable Diffusion web UI の
メイン画面について
メイン画面について
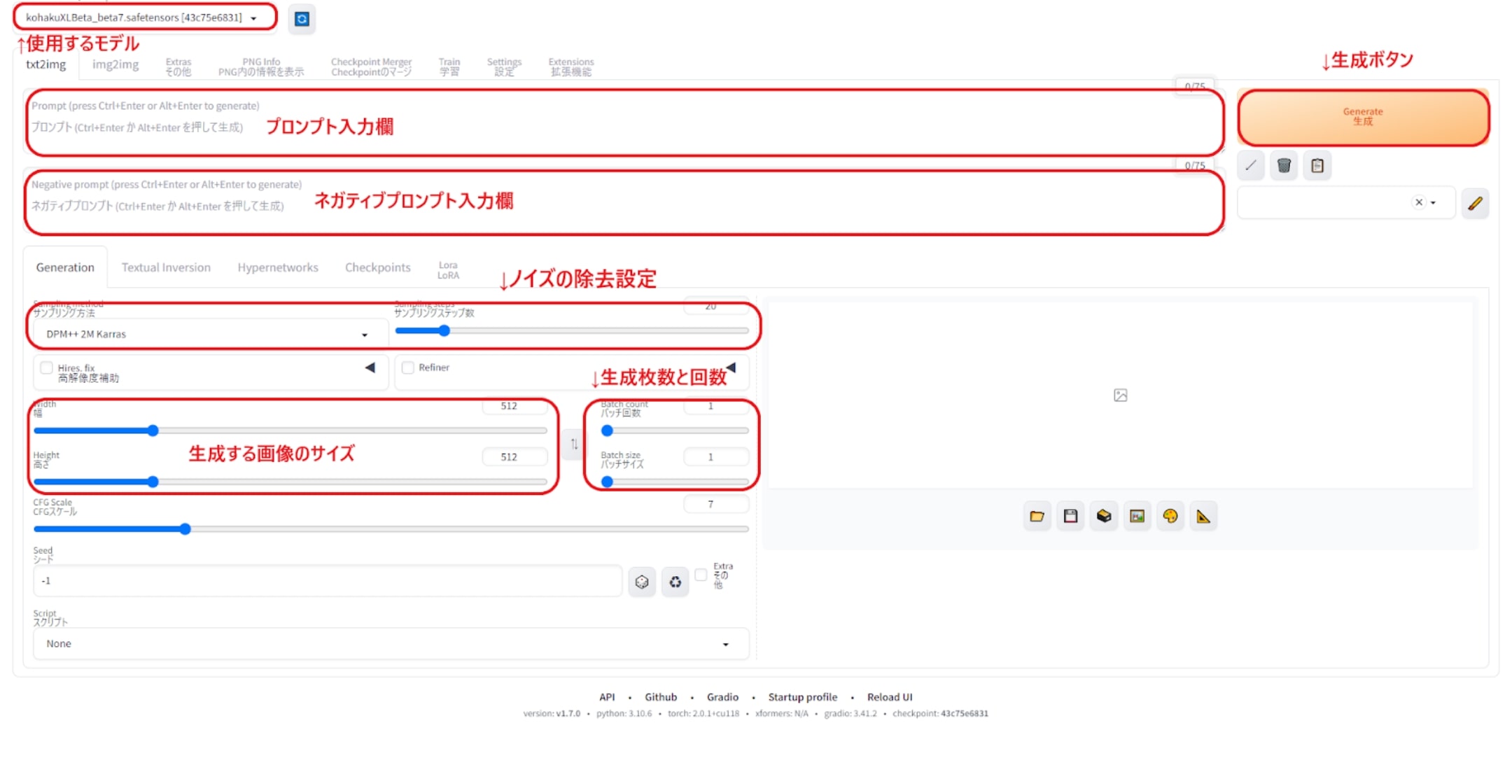
Stable diffusion web UI(Version: v1.7.0)のメイン画面の各項目ですが、メインで使用する項目は以下の6つです。

生成する画像のサイズ、および生成枚数と回数によってGPU性能によって生成完了までの速度が変わります。この辺の条件については、後述のベンチマークにて触れたいと思います。
ノイズの除去設定は、生成される画像の不鮮明さや乱れ=ノイズの修正方法や回数を左右する物で、細かな部分での修正がされます。ただし回数を多くするほど生成速度は遅くなり、修正方法を変える事で生成画像にも変化が現れるようになります。
極端に大きな画像サイスや補正を使っての生成を行うと、VRAM容量不足でのエラーが発生しやすくなります。この点において今回使用しているRTX4060 Ti 16GB版は、VRAM容量が多いGPUなので画像生成AIに適していると言えます。
ノイズの除去設定は、生成される画像の不鮮明さや乱れ=ノイズの修正方法や回数を左右する物で、細かな部分での修正がされます。ただし回数を多くするほど生成速度は遅くなり、修正方法を変える事で生成画像にも変化が現れるようになります。
極端に大きな画像サイスや補正を使っての生成を行うと、VRAM容量不足でのエラーが発生しやすくなります。この点において今回使用しているRTX4060 Ti 16GB版は、VRAM容量が多いGPUなので画像生成AIに適していると言えます。
Stable Diffusion を使い易くする
Stable Diffusionのローカル環境への導入について解説しましたが、まだまだ使用する上での課題が多くあります。
まず言語が全て英語表記であるため、英語に疎い人にとっては使い難いです。ネット上で検索する際には日本語でも各種用語が出てくるので、操作画面に日本語と英語が併記されていた方が分かり易くなります。また導入時点でのデフォルトのモデルを使用しても、イメージした通りの画像が生成される可能性が低いので、追加でモデルを導入する必要があります。特にモデルの導入に関しては画像生成の精度と効率を上げるために、必要不可欠な要素となります。
日英語併記化
-
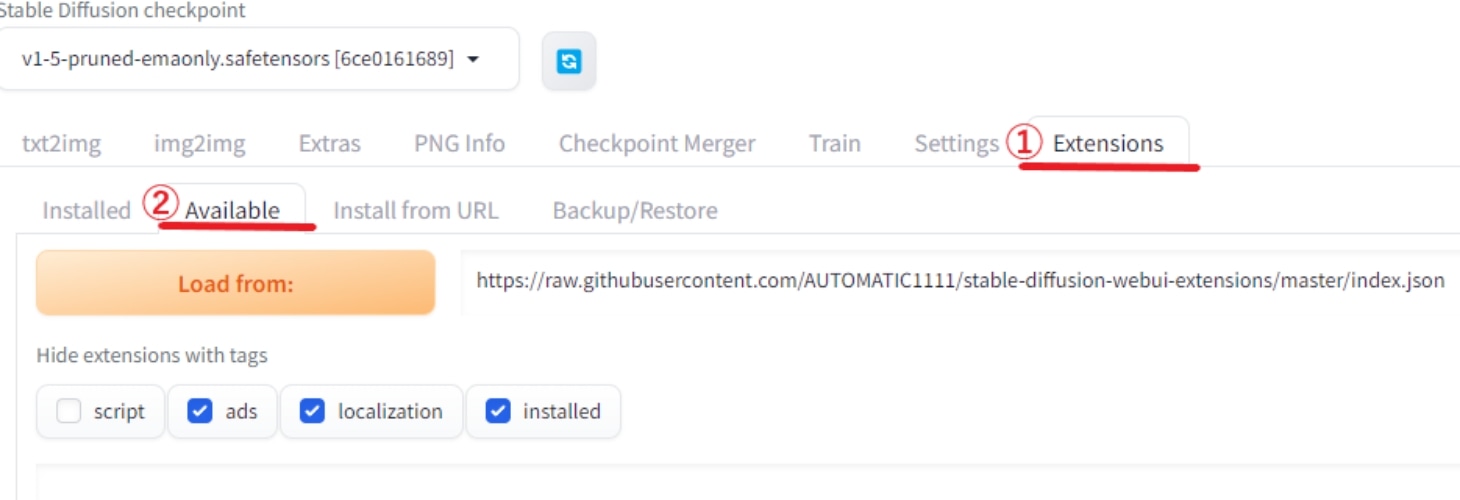
まず①のExtensionsタブを選択し、②のAvailableをクリックします。
-
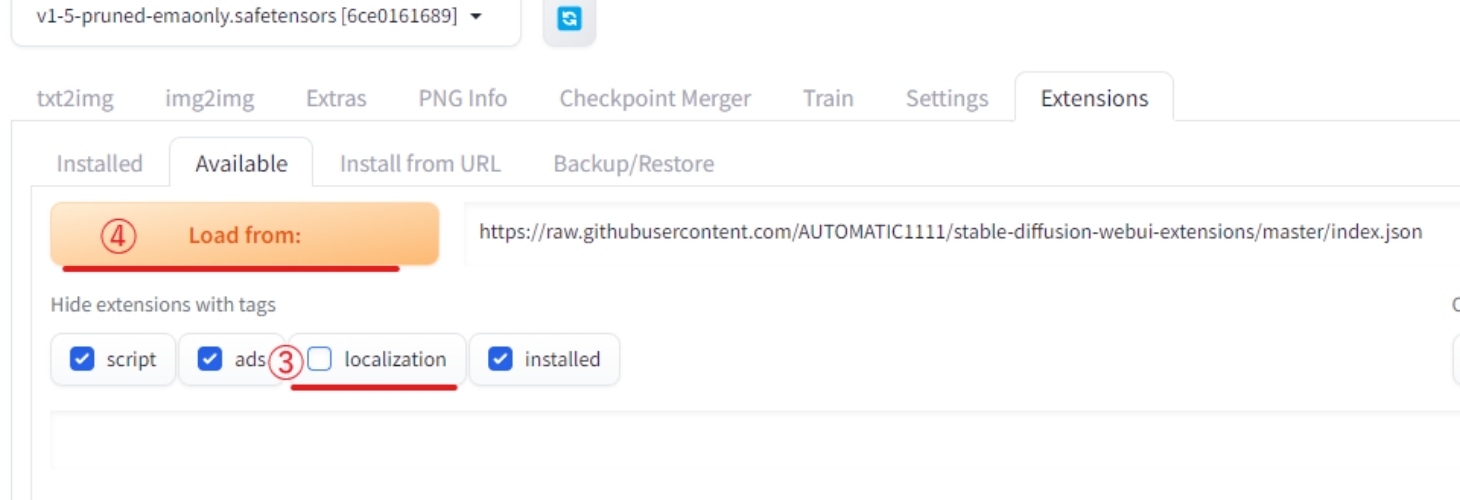
次にHide extensions with tagsにある③のlocalizationのチェックを外し、それ以外の項目にチェックを付けたら、④のLoad fromをクリックします。
-
すると各種言語リストが出てきますので、「ja_JP Localization」の項目のInstallをクリックします。
Ctrl+Fキーを押せばページ内の検索バーが出ますので、それを利用すると一覧から探すのが容易となります。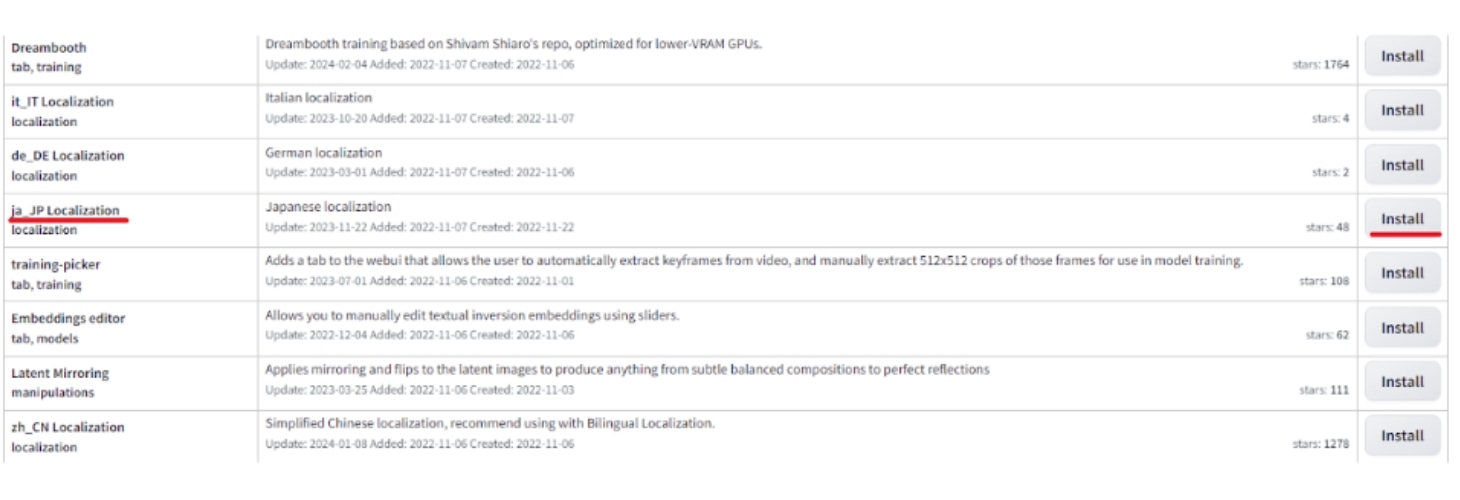
-
インストール後、⑤のSettingsタブからLocalization (requires restart)の項目を探し、⑥のドロップダウンリストからja-JPがあることを確認し、確認後はNoneに戻します。
Ja-JPが出てこない場合は、右にあるアイコンを押してリロードしてみてください。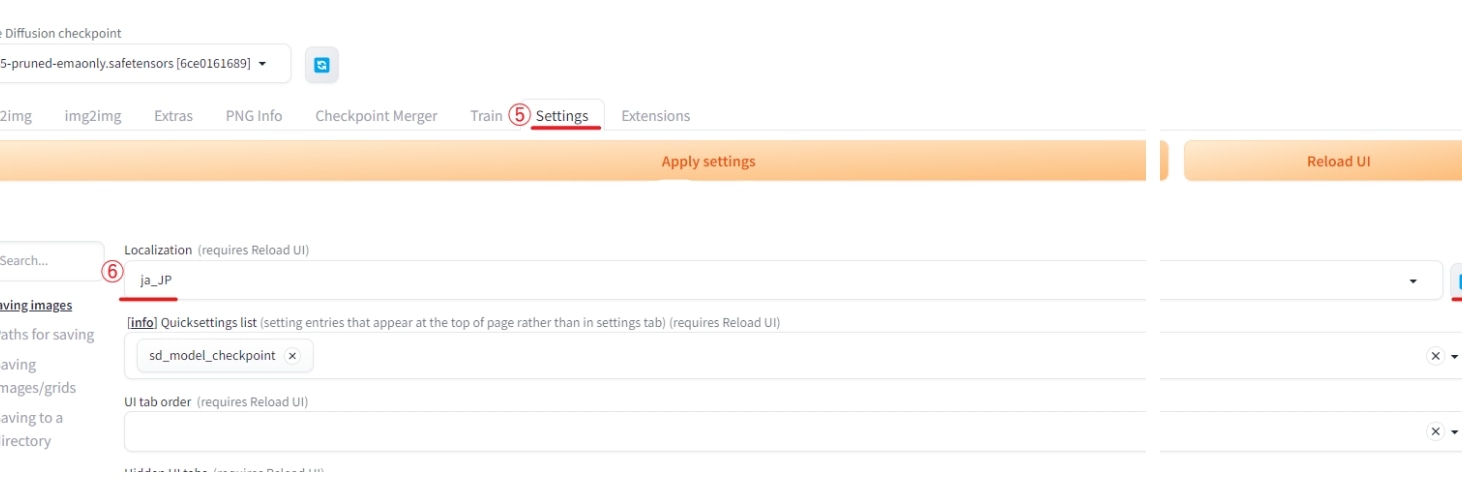
-
最後にSettings - Bilingual Localizationパネルから、⑦で「ja_JP」を選択し、⑧のApply setting、⑨のReload UIの順番でクリックすれば日英併記となります。
上手く併記されていない場合はユーザーインターフェースの言語設定(Localization)がNone Bilingual Localizationの言語設定がja_JPになっているか確認してみてください。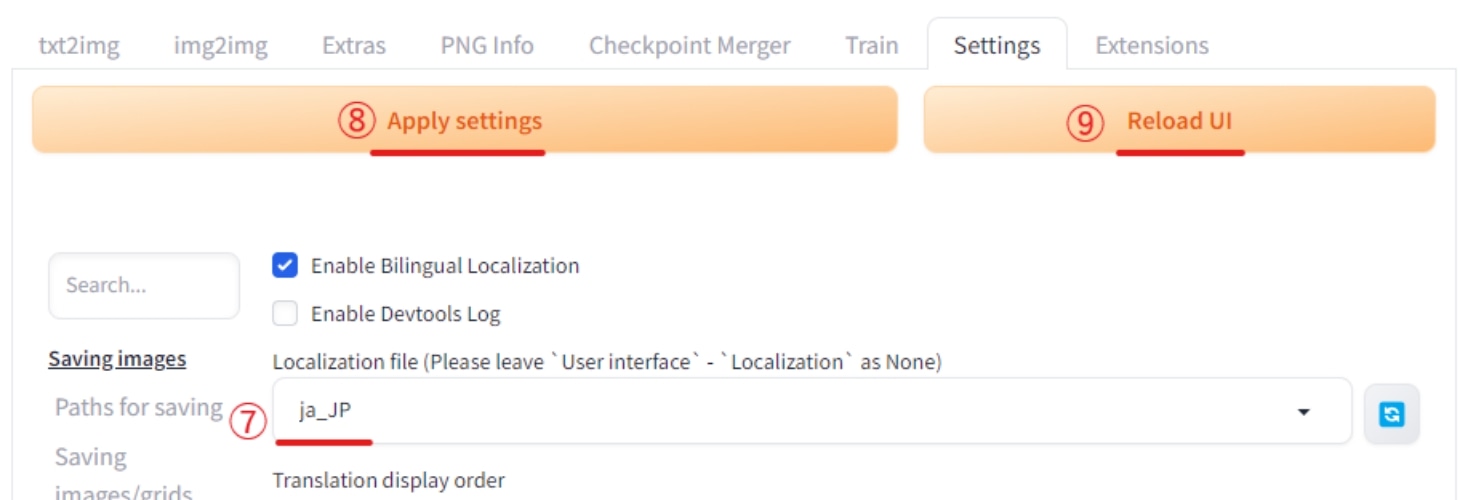
モデルを導入する方法
ここで言う「モデル」とはAIが予め学習して得たデータ、人間でいうところの経験値と言える物です。このモデルによって得意な画風やジャンルがあり、ユーザーのイメージに近いモデルを導入することで、高いクオリティの画像を生成してくれるようになります。Stable Diffusion導入時点で用意されるデフォルトのモデルもあるのですが、それを使って理想とする画像を生成するのは難しいです。
-
モデルの配布サイトは「civitai」「Hugging Face」などがありますが、今回はcivitaiでモデル導入してみます。もし写真やフォトグラフィックのようなリアル系画像を生成したい方は、それに適したモデルを導入してください。
モデルには「CHECKPOINT MERGE」と「LoRA」があり、CHECKPOINT MERGEは基本的な画風などを決める根幹モデル、LoRAは背景、服装、キャラクターなどの細部を決める追加学習データとなります。
-
導入モデルは「AbyssOrangeMix2 - SFW/Soft NSFW」です。ページのdownloadよりダウンロードを行います。
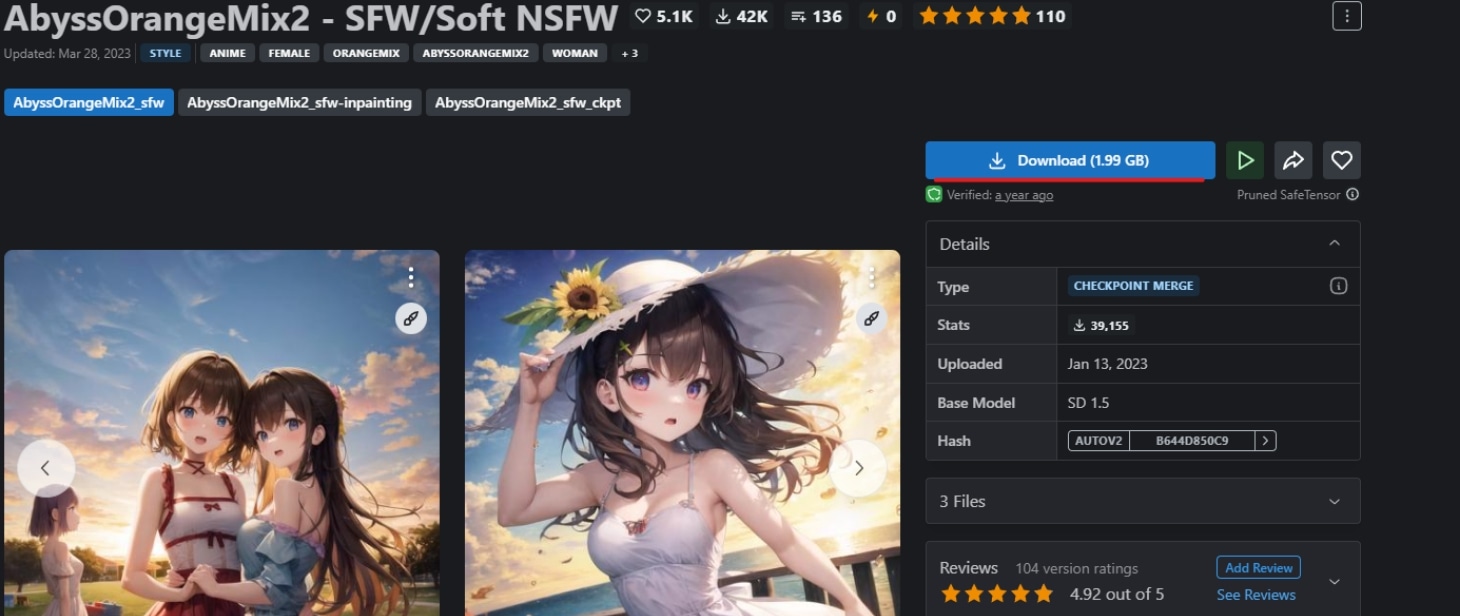
-
ダウンロードしたファイルを、stable-diffusion-webui内の「models → Stable-diffusion」内へとファイルを移動します。
これでモデル導入は完了です。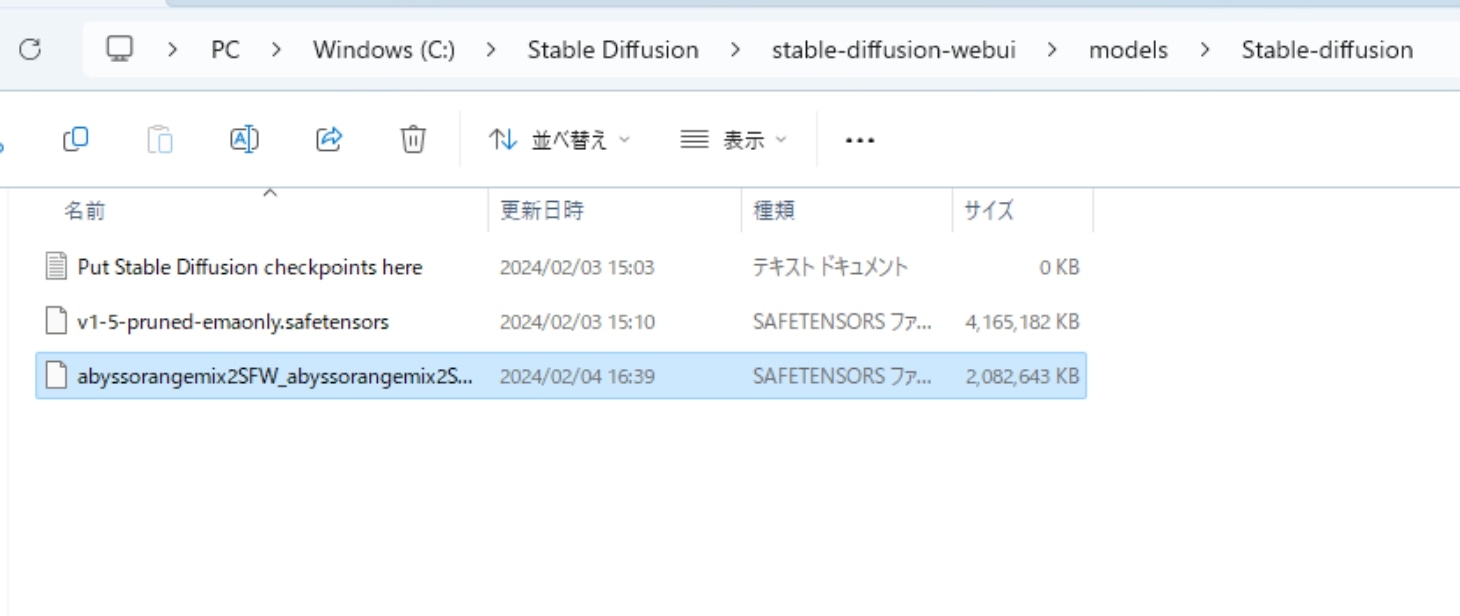
Stable Diffusion で
画像生成を始めましょう
画像生成を始めましょう
まずはデフォルトモデルを使った場合での基本編、そして見本となる生成画像のプロンプトを利用した応用編を紹介し、最後に生成にかかる時間などについてのベンチマークをしていきます。
基本編
とりあえず最初は、冒頭の例でも取り上げた「犬」をテーマに生成をしてみましょう。
プロンプト欄に日本語で「犬」とだけ入力して、複数枚ランダム生成してみます。
プロンプト欄に日本語で「犬」とだけ入力して、複数枚ランダム生成してみます。
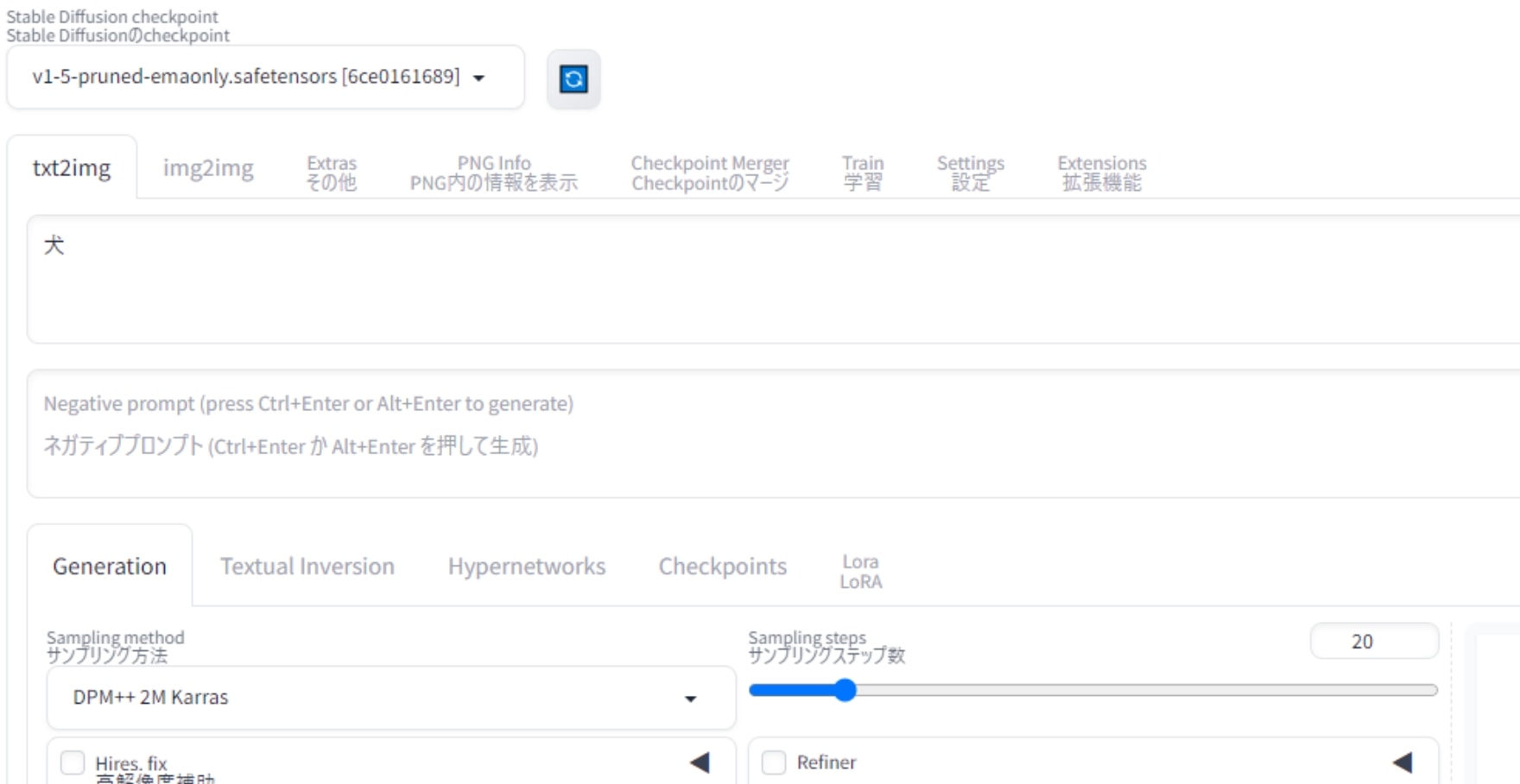

するとこの様な感じに。
日本語でも単純な単語や文章であれば認識されますが、それでも精度は低いため、作画崩壊した生成結果となることも多いです。6枚単位でそれなりに綺麗な結果が出揃ったのは、かなり運が良かったと言えます。
次は犬種や背景をもう少し絞ったプロンプトを試してみましょう。
日本語でも単純な単語や文章であれば認識されますが、それでも精度は低いため、作画崩壊した生成結果となることも多いです。6枚単位でそれなりに綺麗な結果が出揃ったのは、かなり運が良かったと言えます。
次は犬種や背景をもう少し絞ったプロンプトを試してみましょう。
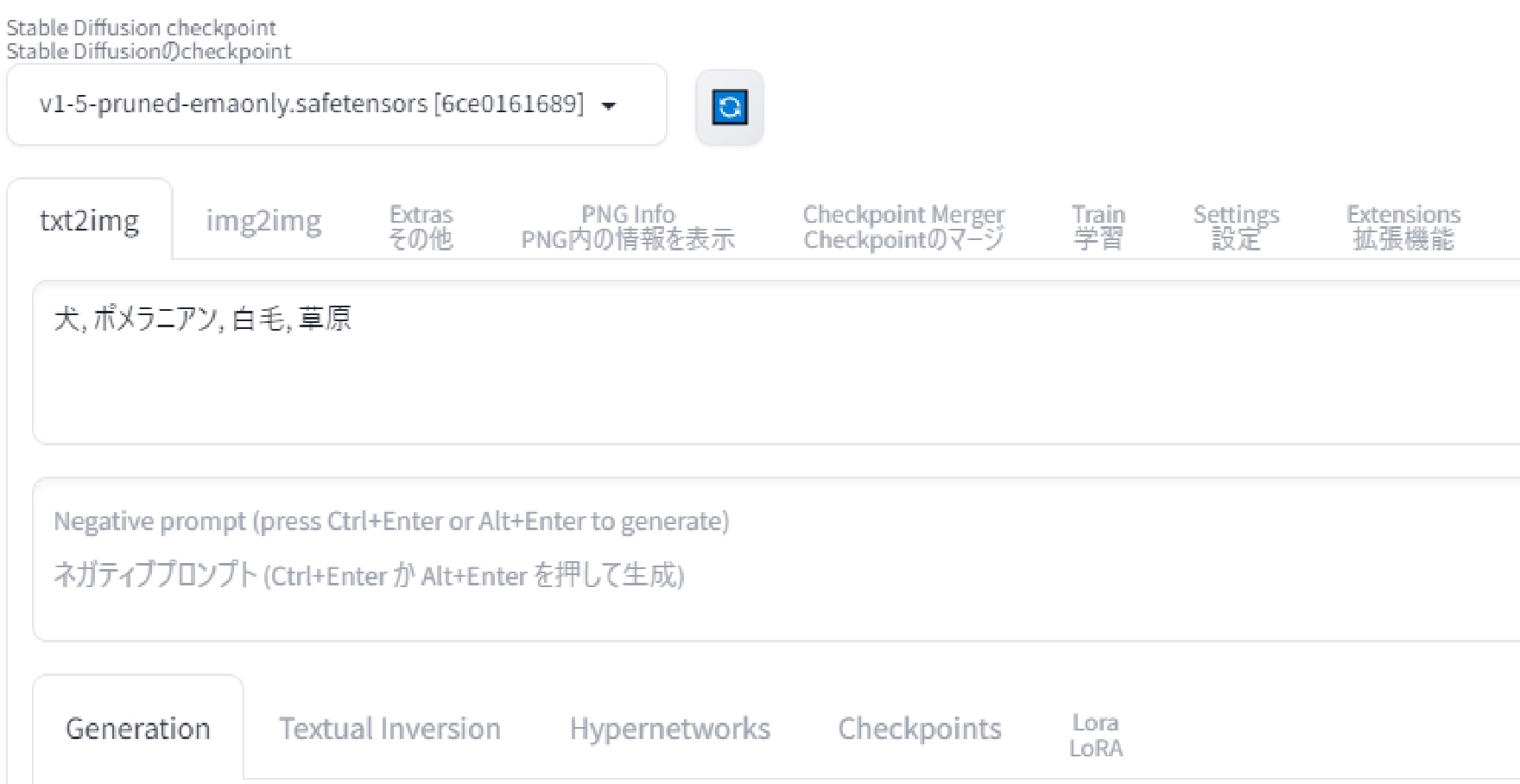
こちらも冒頭の例に出した「犬, ポメラニアン, 白毛, 草原」を入力しました。実写という要素はモデルによって既に実写っぽくなっているので、今回は省略しました。

結果はこちら。
辛うじて「犬」は認識されているかな…?という怪しい結果に。
この後1単語ずつで生成してみましたが、やはり認識されないと思われる単語が目立ちました。「草原」という単語ですら、ビルやアスファルトが目立つ街並みが生成される有様です。この辺が「日本語入力での精度の低さ」と言われている要因かと思われます。
次に英単語で「dog, a pomeranian, white hair, grassland」と入力してみます。
辛うじて「犬」は認識されているかな…?という怪しい結果に。
この後1単語ずつで生成してみましたが、やはり認識されないと思われる単語が目立ちました。「草原」という単語ですら、ビルやアスファルトが目立つ街並みが生成される有様です。この辺が「日本語入力での精度の低さ」と言われている要因かと思われます。
次に英単語で「dog, a pomeranian, white hair, grassland」と入力してみます。
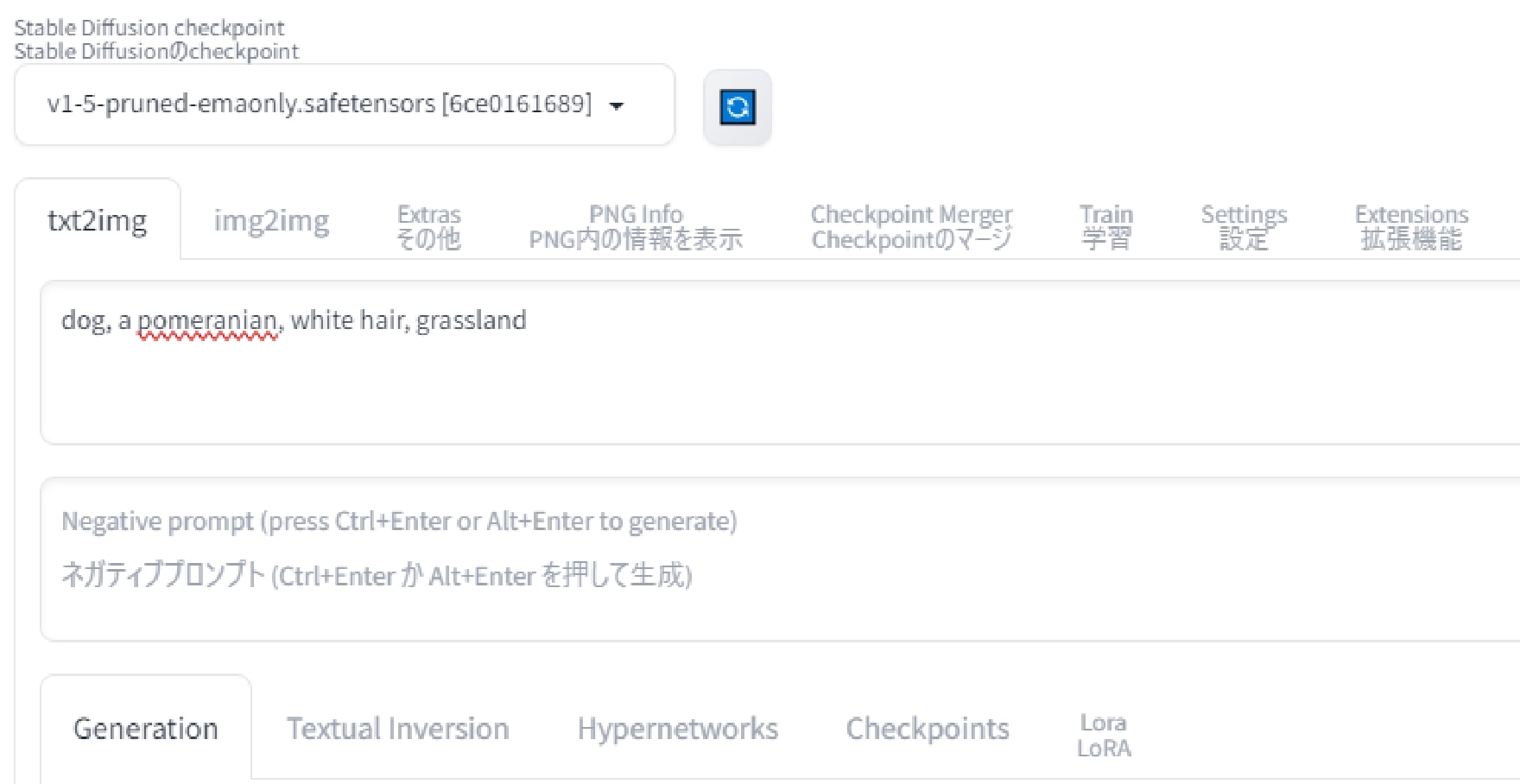
ちなみに今回はスペルミスも防ぐために、Googleの翻訳機能による簡単な英単語を使用しています。

すると、かなりポメラニアンっぽい犬が複数回ヒットしました。草原という条件も上手く認識されており、全て草地の地面となっています。
以上の事から「プロンプト入力は英単語で行うとAIから認識されやすく、生成される画像の精度が上がる」ということが分かりました。翻訳機能で分かる程度の単語でも十分機能しますので、「とりあえず思い浮かんだイメージの日本語を英単語にして、プロンプトに入力してみる」というのが画像生成AIの基本となります。
以上の事から「プロンプト入力は英単語で行うとAIから認識されやすく、生成される画像の精度が上がる」ということが分かりました。翻訳機能で分かる程度の単語でも十分機能しますので、「とりあえず思い浮かんだイメージの日本語を英単語にして、プロンプトに入力してみる」というのが画像生成AIの基本となります。
応用編
次に既存のAI生成画像で使用されたプロンプトなどのデータを参照し、そこから新たに生成する方法について解説します。
まずは「AbyssOrangeMix2 - SFW/Soft NSFW」のダウンロードページにも掲載されている、こちらの画像を見本にして生成します。
まずは「AbyssOrangeMix2 - SFW/Soft NSFW」のダウンロードページにも掲載されている、こちらの画像を見本にして生成します。

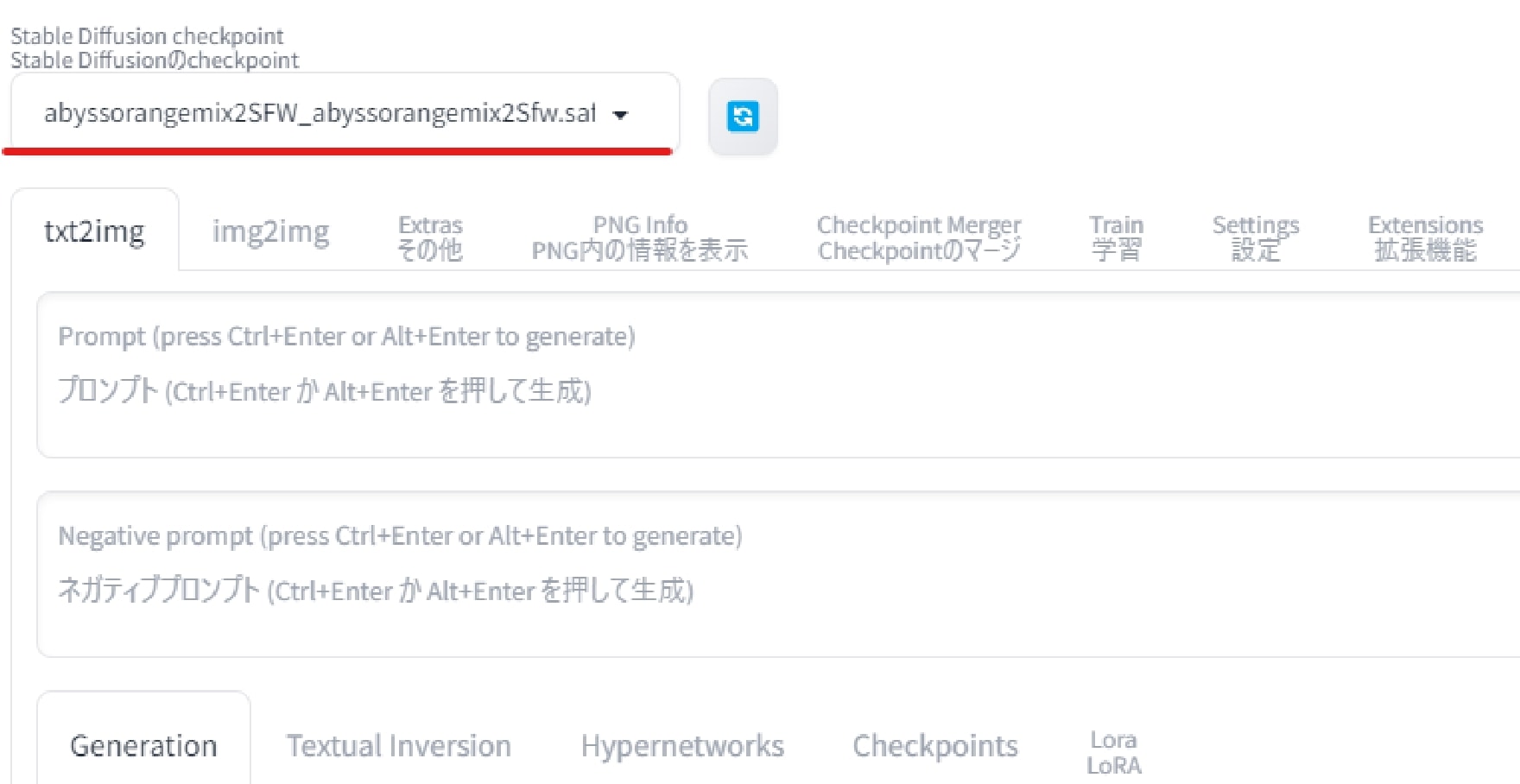
まずは導入モデルを同じにします。
Stable Diffusionのメイン画面の、左上から使用するモデルを変更します。
Stable Diffusionのメイン画面の、左上から使用するモデルを変更します。
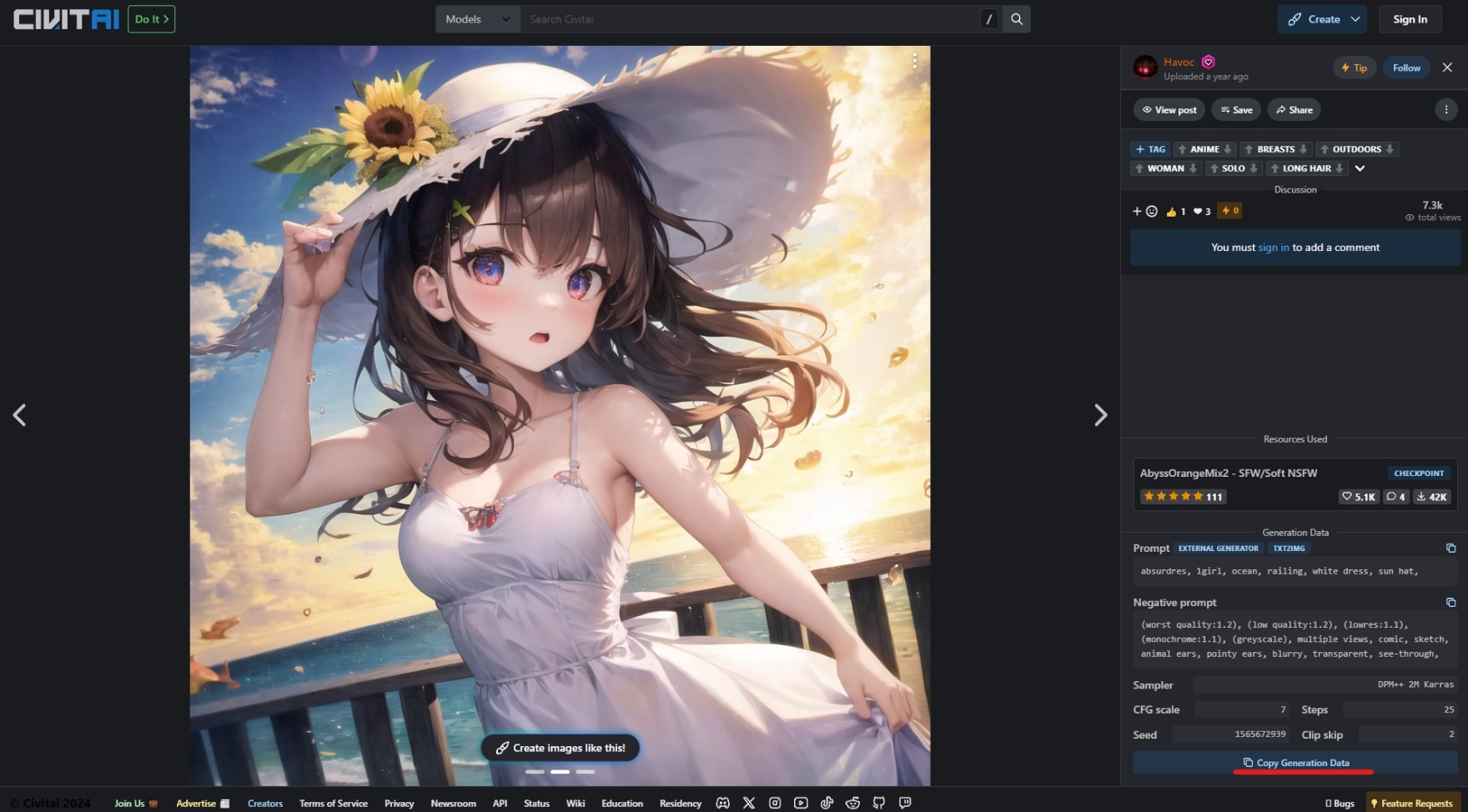
生成するうえで重要となるプロンプトですが、civitaiで閲覧できる画像の詳細を開くことで確認可能。
生成時のプロンプトのコツとしては
●単語の順番に気を付ける
●単語と単語の間には「カンマ(, )+半角スペース」を入れる
●排除したい要素=ネガティブプロンプトを入力する
と言った事が挙げられます。今回は見本と同じ画像を生成したいので、プロンプトなどのデータは全て同じものを使います。
ページ右下の「Copy Generation Data」をクリックしてデータをコピーすれば、全てのデータが一括コピーされます。
生成時のプロンプトのコツとしては
●単語の順番に気を付ける
●単語と単語の間には「カンマ(, )+半角スペース」を入れる
●排除したい要素=ネガティブプロンプトを入力する
と言った事が挙げられます。今回は見本と同じ画像を生成したいので、プロンプトなどのデータは全て同じものを使います。
ページ右下の「Copy Generation Data」をクリックしてデータをコピーすれば、全てのデータが一括コピーされます。
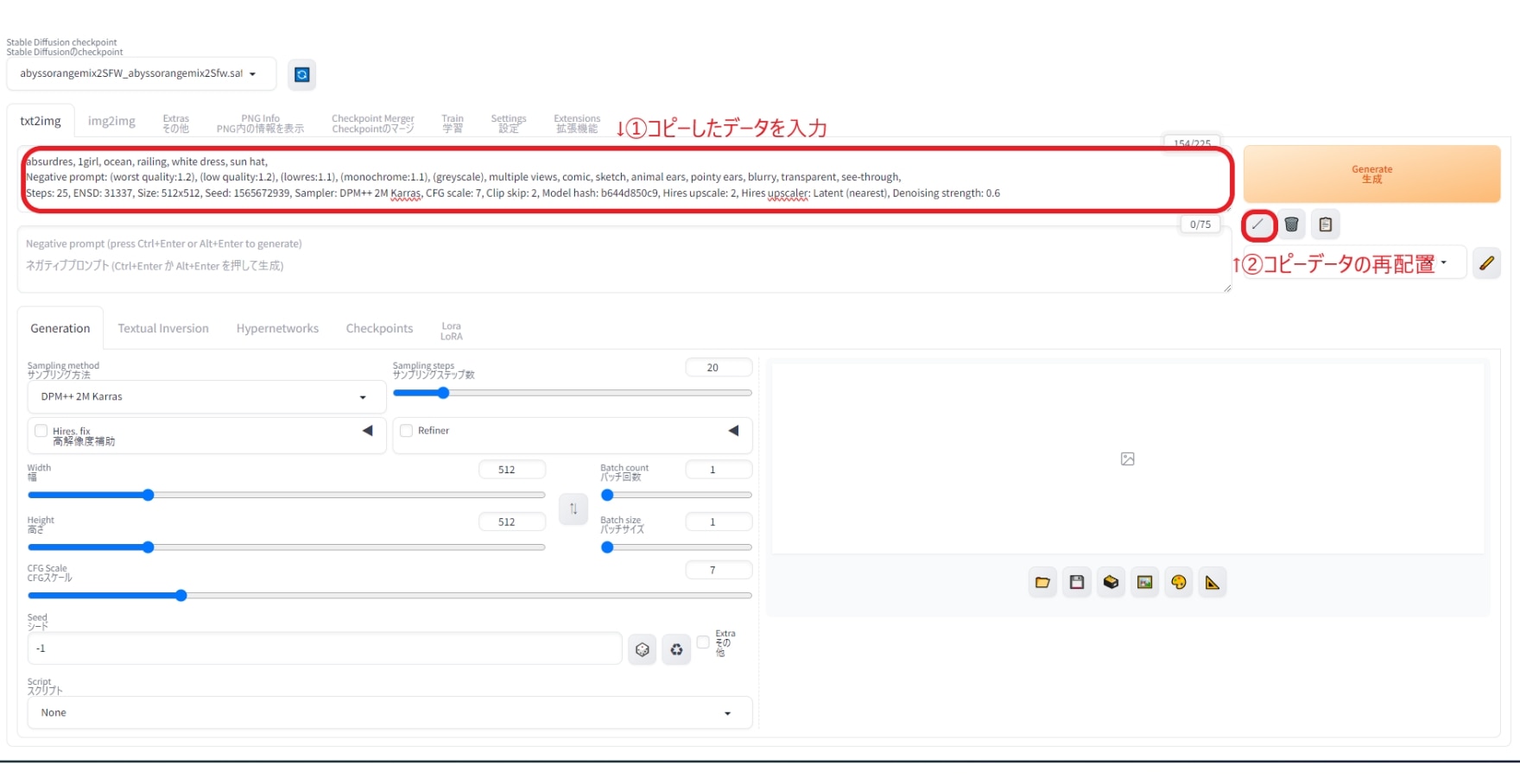
コピーしたデータをStable Diffusion上で反映させるのも簡単です。
1.コピーしたデータをプロンプト欄に入力
2.生成ボタン左下の矢印ボタンをクリックし、コピーデータの再配置
以上を行って生成を開始しますと…
1.コピーしたデータをプロンプト欄に入力
2.生成ボタン左下の矢印ボタンをクリックし、コピーデータの再配置
以上を行って生成を開始しますと…
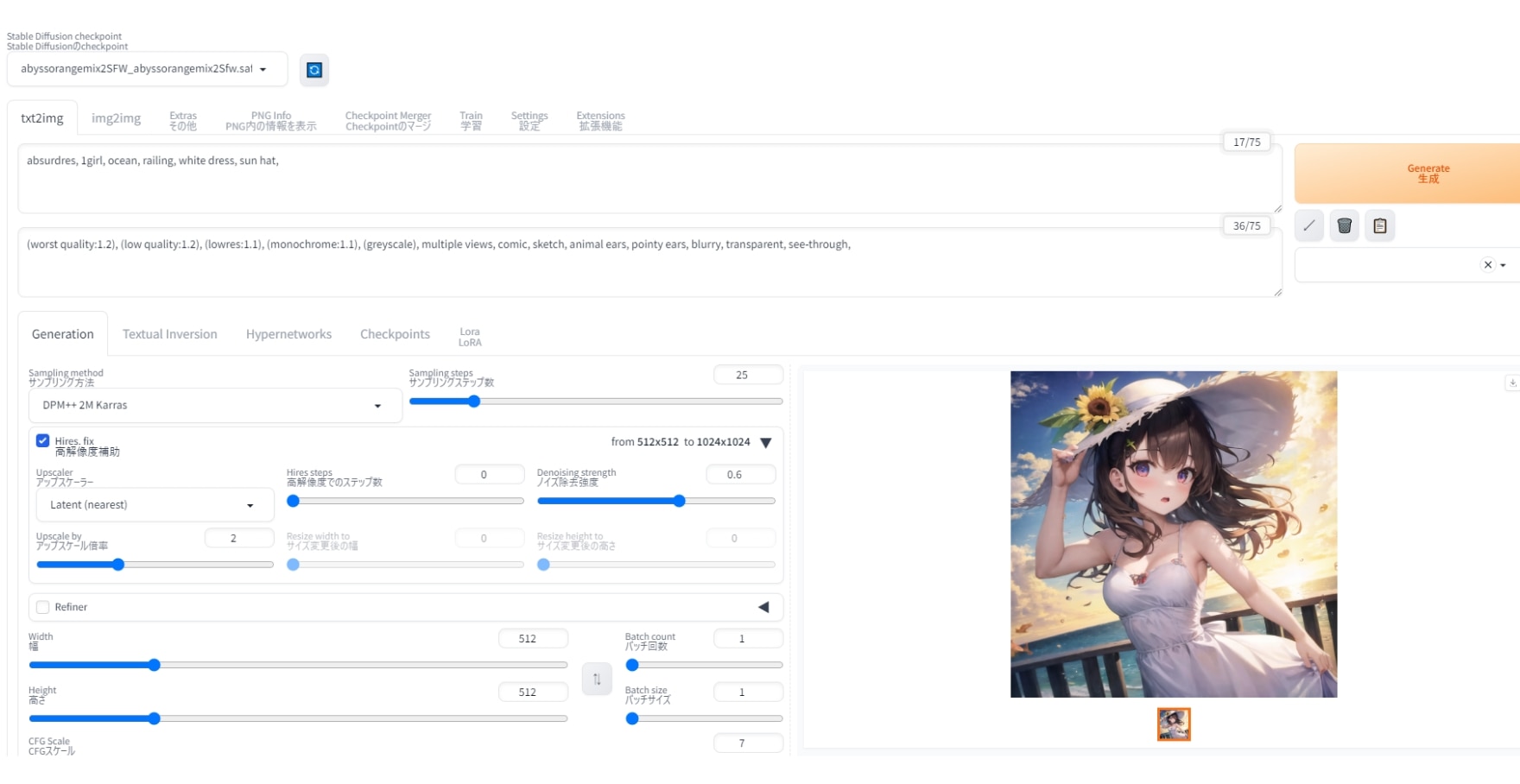
この様に全く同じ画像が生成されます。
あとはプロンプトやネガティブプロンプトを追加・削除の試行錯誤をしてみましょう。
ちなみに見本からネガティブプロンプト無しの状態での生成も試してみたところ、今度は油絵のような画風になりました。
使用しているモデルなどは全く同じですが、ネガティブプロンプトの有無だけでも画風が大きく変わる可能性があるということが、これで分かるかと思います。
ちなみに見本からネガティブプロンプト無しの状態での生成も試してみたところ、今度は油絵のような画風になりました。
使用しているモデルなどは全く同じですが、ネガティブプロンプトの有無だけでも画風が大きく変わる可能性があるということが、これで分かるかと思います。

ベンチマーク
次に既存のAI生成画像で使用されたプロンプトなどのデータを参照し、そこから新たに生成する方法について解説します。
まずは「AbyssOrangeMix2 - SFW/Soft NSFW」のダウンロードページにも掲載されている、こちらの画像を見本にして生成します。
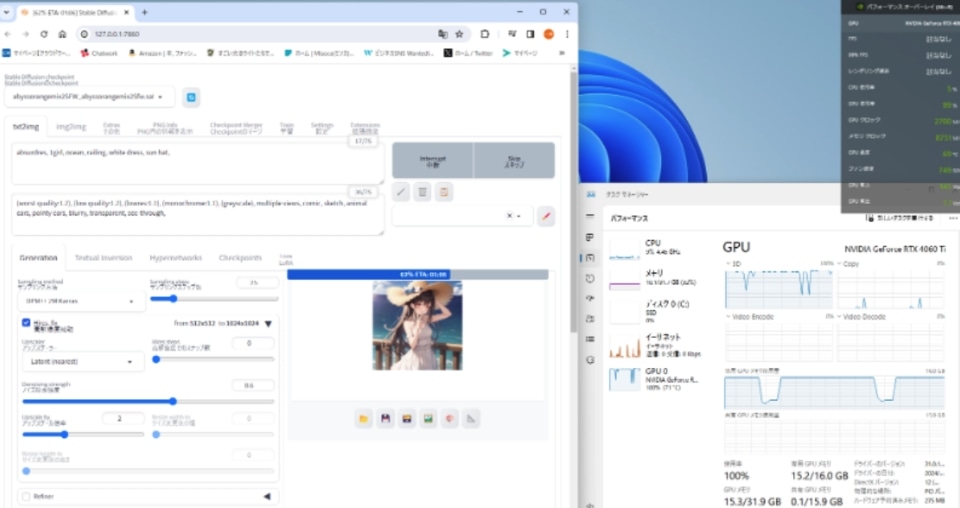
またプロンプトなどは同じでも、シード値を-1に設定することでランダム生成が可能です。今回は生成時間のベンチマークとして、モデル配布ページの画像と同じデータを使用し、シード値は-1=ランダムにして512×512サイズで6枚連続生成。生成時間はおおよそ3分ほどかかりました。
次にバッチサイズ6にしての6枚同時生成を試みましたが、こちらもおおよそ3分で生成。今回の条件では生成時間に大きな差は現れませんでした。
ただしタスクマネージャー上でVRAMの使用率などを観察すると、連続生成では16GB近くまで使うのに対して、同時生成では2割ほど余裕を残して生成されていました。
この辺りの挙動は生成する画像の解像度、GPUのスペックなどによっても変わります。より効率よく短時間で生成するには、生成枚数と回数を様々な比率で試してみるといいでしょう。
次にバッチサイズ6にしての6枚同時生成を試みましたが、こちらもおおよそ3分で生成。今回の条件では生成時間に大きな差は現れませんでした。
ただしタスクマネージャー上でVRAMの使用率などを観察すると、連続生成では16GB近くまで使うのに対して、同時生成では2割ほど余裕を残して生成されていました。
この辺りの挙動は生成する画像の解像度、GPUのスペックなどによっても変わります。より効率よく短時間で生成するには、生成枚数と回数を様々な比率で試してみるといいでしょう。

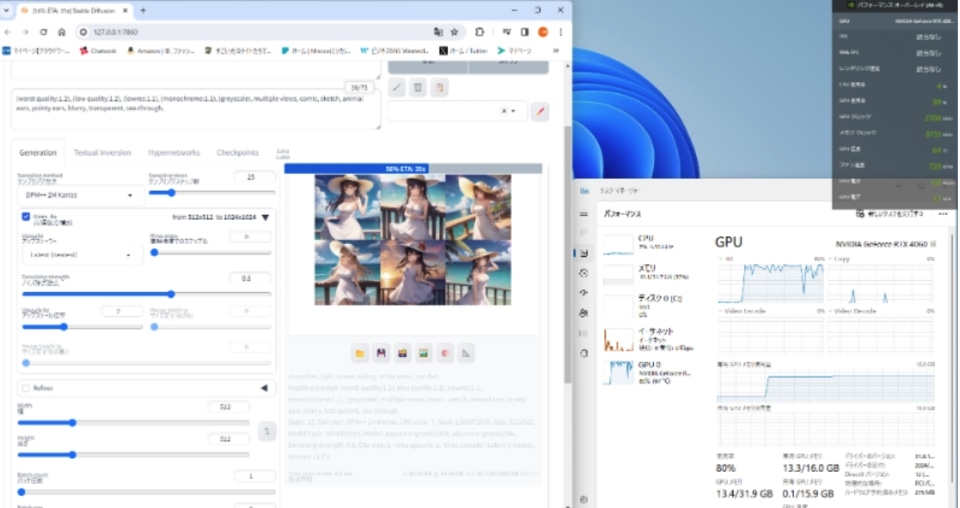
まとめ
今や人間以上の成果を出すこともあるAIは、近い将来 一部の職業をAIが取って代わる時代が来るとも言われています。画像生成AIもその一つで、イラストレーターや写真家などのクリエイターに変化をもたらす可能性があります。
そんな画像生成AIですが、その処理に巨大なスーパーコンピューターなどは不要。簡単に個人で入手できるパソコンで稼働させることが可能です。
一応PCスペックや生成された画像の取り扱い条件などはありますが、ポイントを押さえて条件を満たせば、画像生成AI分野への参入は容易となっています。これからStable Diffusionを利用する方は、今回紹介したPCなどを参考にして最適な作業環境を導入しましょう。
そんな画像生成AIですが、その処理に巨大なスーパーコンピューターなどは不要。簡単に個人で入手できるパソコンで稼働させることが可能です。
一応PCスペックや生成された画像の取り扱い条件などはありますが、ポイントを押さえて条件を満たせば、画像生成AI分野への参入は容易となっています。これからStable Diffusionを利用する方は、今回紹介したPCなどを参考にして最適な作業環境を導入しましょう。